

Entenda os princípios para desenvolver um agente de recomendação para aplicação em e-commerces e outros serviços como Netlfix, Amazon e Spotify
As vendas online dispararam no último ano no Brasil, aumentando em 75% no varejo. Com ela cresceu também um movimento de agentes de recomendação, responsáveis por ajudar os consumidores a escolherem os produtos ou serviços mais adequados para a sua situação – e também impulsionar a decisão de compra.
Esses agentes podem ser humanos ou sistemas automatizados de Inteligência Artificial – que possibilitam uma experiência do cliente diferenciada e um aumento em escala no atendimento. Exemplos desses agentes são encontrados na Magazine Luiza, Natura e Casas Bahia, inclusive com traços de humanização dos personagens. Para entender mais a fundo esse contexto, acesse a pesquisa realizada pela Ilumeo sobre agentes de recomendação: Humanos vs IAs.
Foram também os sistemas automatizados de recomendação que contribuíram para tornar a Amazon o que é hoje: eles sempre foram muito bons em recomendar quais livros o usuário deveria ler. Existem muitas outras empresas que são construídas em torno desses sistemas, como as sempre queridinhas YouTube, Netflix e Spotify. Em paralelo, os consumidores passaram a esperar uma experiência personalizada e sistemas de recomendação sofisticados para encontrar produtos e conteúdos relevantes.
Mas como é construído um mecanismo de recomendação? Neste post vamos detalhar os principais aspectos técnicos desse desenvolvimento para que você entenda o que ocorre “na cozinha” de um sistema de recomendação.
Como construir um mecanismo de recomendação
Em artigo no Medium, o cientista de dados britânico Jan Teichmann explica que há alguns aprendizados importantes a se levar em consideração no desenvolvimento de um sistema de recomendação. Primeiro, que as ações de um usuário são o melhor indicador da intenção do usuário. As classificações e o feedback tendem a ser muito tendenciosos e com volumes mais baixos. Segundo, que as ações e compras anteriores geram novas compras e a sobreposição com as compras e ações de outras pessoas é um ótimo indicador dessa intenção.
Assim, os sistemas de recomendação geralmente procuram sobreposição ou coocorrência para fazer uma recomendação. Como no exemplo a seguir, onde se recomenda o cachorro Ethan com base em uma semelhança de Ethan com a pessoa Sophia:

Ilustração encontrada em “Practical Machine Learning”, de Ted Dunning & Ellen Friedman, O’Reilly 2014
Na prática, um mecanismo de recomendação calcula uma matriz de coocorrência a partir de uma matriz de histórico de eventos e ações. Isso é bastante simples, mas há desafios a serem superados em cenários do mundo real. E se todo mundo quiser um unicórnio? A alta coocorrência de unicórnios no exemplo a seguir é uma boa recomendação?

Ilustração encontrada em “Practical Machine Learning”, de Ted Dunning & Ellen Friedman, O’Reilly 2014
Após o sistema de recomendação ter calculado a matriz de coocorrência, temos que aplicar estatísticas para filtrar os sinais suficientemente anômalos para serem interessantes como uma recomendação.

Ilustração encontrada em “Practical Machine Learning”, de Ted Dunning & Ellen Friedman, O’Reilly 2014
Os algoritmos e estatísticas que podem extrair indicadores relevantes da matriz de coocorrência são o que torna um bom sistema de recomendação. O caminho de criação de uma matriz de indicador item a item é chamado de modelo item-item. Obviamente, também há um modelo de user-item:
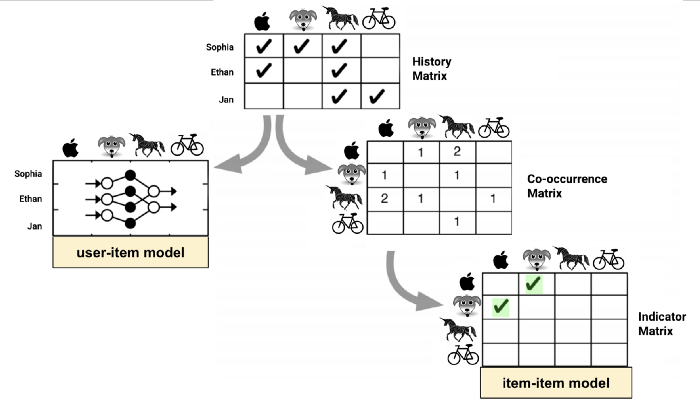
Para criar um modelo user-item, é possível aplicar uma fatoração de matriz simples ou treinar uma rede neural para prever as pontuações de uma entrada de user-item. Normalmente, os modelos item-item são mais robustos e produzem melhores resultados quando não é possível investir em engenharia de recursos e ajustes de modelos, etc.
De forma básica é assim que tecnicamente funciona um sistema de recomendação. Há diversas particularidades dependendo de onde o sistema é aplicado – se recomenda livros, filmes ou produtos de varejo, por exemplo. Ainda assim, de forma generalizada, os sistemas de recomendação funcionam melhor com feedback explícito e imparcial do usuário, como a compra de produtos, assistir a um vídeo ou ouvir uma música.
No entanto, em muitos casos, há o feedback implícito, como visualizações de página, cliques ou consultas de pesquisa. Esses dados também são muito tendenciosos, por exemplo: a taxa de cliques depende muito da posição do conteúdo em uma página. Esse feedback implícito também tende a ter um desempenho pior, como um clique em um resultado de pesquisa pode apenas ensinar a você sobre como o clickbaity é um título ou call to action, em vez da relevância do conteúdo real. Isso resulta em altas taxas de rejeição após taxas de cliques inicialmente altas – um caso muito comum, inclusive.
Aqui entra a filtragem colaborativa, que requer coocorrência entre os itens. Isso significa que a filtragem colaborativa é adequada e levará a bons resultados se:
-
O catálogo de produtos não for muito grande, os itens duram muito e podem facilmente receber interações por vários usuários. Vamos usar o Zoopla como um exemplo em que temos problemas: Zoopla.co.uk é um portal de propriedades e tem mais de 1,3 milhões de anúncios ao vivo a qualquer momento. Um anúncio de aluguel em Londres dura muito pouco e pode levar dias até que um imóvel seja alugado e retirado do mercado. Obviamente, você se pode alugar ou vender um apartamento para várias pessoas ao mesmo tempo! Com o tamanho do catálogo Zoopla, é realmente difícil gerar uma quantidade significativa de coocorrência, mesmo com os volumes de tráfego elevados no site.
-
Não depende de recomendações para a descoberta de novos produtos. Como a filtragem colaborativa requer coocorrência para gerar sinais, o algoritmo tem um grande problema de inicialização a frio. Qualquer novo item no catálogo de produtos não tem coocorrência e não pode ser recomendado sem algum envolvimento inicial dos usuários com o novo item. Isso pode ser aceitável se a empresa usar, por exemplo, muito CRM e marketing digital como estratégia para promover novos produtos.
Há casos muito mais avançados e detalhados de mecanismos de recomendação, mas o importante aqui é também citarmos o mindset da construção desses mecanismos. Em outro de seus artigos no Medium, Jan Teichmann sugere que um mecanismo de recomendação seja implantado de forma gradual em uma empresa, por partes. Aqui, o importante não é desenvolver de cara o mecanismo perfeito, mas começar com uma versão inicial mais básica e que funcione como primeiro ponto de coleta de dados para, a partir dessas interações, criar versões mais aprimoradas. Na prática, isso significa construir a versão 1.1, 1.2 e 1.3 muito antes de iniciar qualquer trabalho na versão 2.
Mais ou menos como o passo a passo da ilustração abaixo:

Para desenvolver uma primeira versão de mecanismo de recomendação há várias opções, dependendo do ponto de partida:
-
Se há conhecimento profundo dos produtos ou há metadados ricos disponíveis, é possível construir um mecanismo de regras simples capturando a lógica de negócios primeiro. Com um foco de entrega ágil e pragmático em mente, é importante saber quando o aprendizado de máquina não é necessário.
-
Se há conhecimento a fundo dos usuários, é viável personalizar o mecanismo de regras com o uso de alguma segmentação de usuário básica, por exemplo, RFM.
-
Mas na maioria das vezes não sabemos o suficiente ou mesmo nada sobre os usuários e produtos. Tudo o que temos são dados de fluxo de cliques comportamentais das interações do usuário com o site ou os produtos. Nesse caso, devemos considerar o uso da filtragem colaborativa que explicamos anteriormente para construir a primeira versão do mecanismo de recomendação.
Esses são os princípios gerais que rolam por trás dos mecanismos de recomendação e que oferecem experiências personalizadas para usuários – que já preferem a atuação de um agente de IA ao invés de recomendações humanas, como mostra o estudo da Ilumeo. Uma vez que esses sistemas se tornem cada vez mais populares e difundidos, se tornarão prioridade nas empresas que desejam ser competitivas e eficientes para conquistar e reter consumidores.


