Cientista chefe do Google explica o funcionamento do aprendizado de máquina com uma linguagem leiga e divertida.
Machine Learning usa padrões de dados para rotular as coisas. Segundo Cassie Kozyrkov, cientista chefe do Google, esse é o conceito central por trás do aprendizado de máquina, sem qualquer mágica ou misticismo. Para ilustrar o funcionamento dessa “rotulação de coisas”, ela sugere um programa que seja capaz de discernir vinhos bons e ruins. Pois bem, como funciona?
Dados
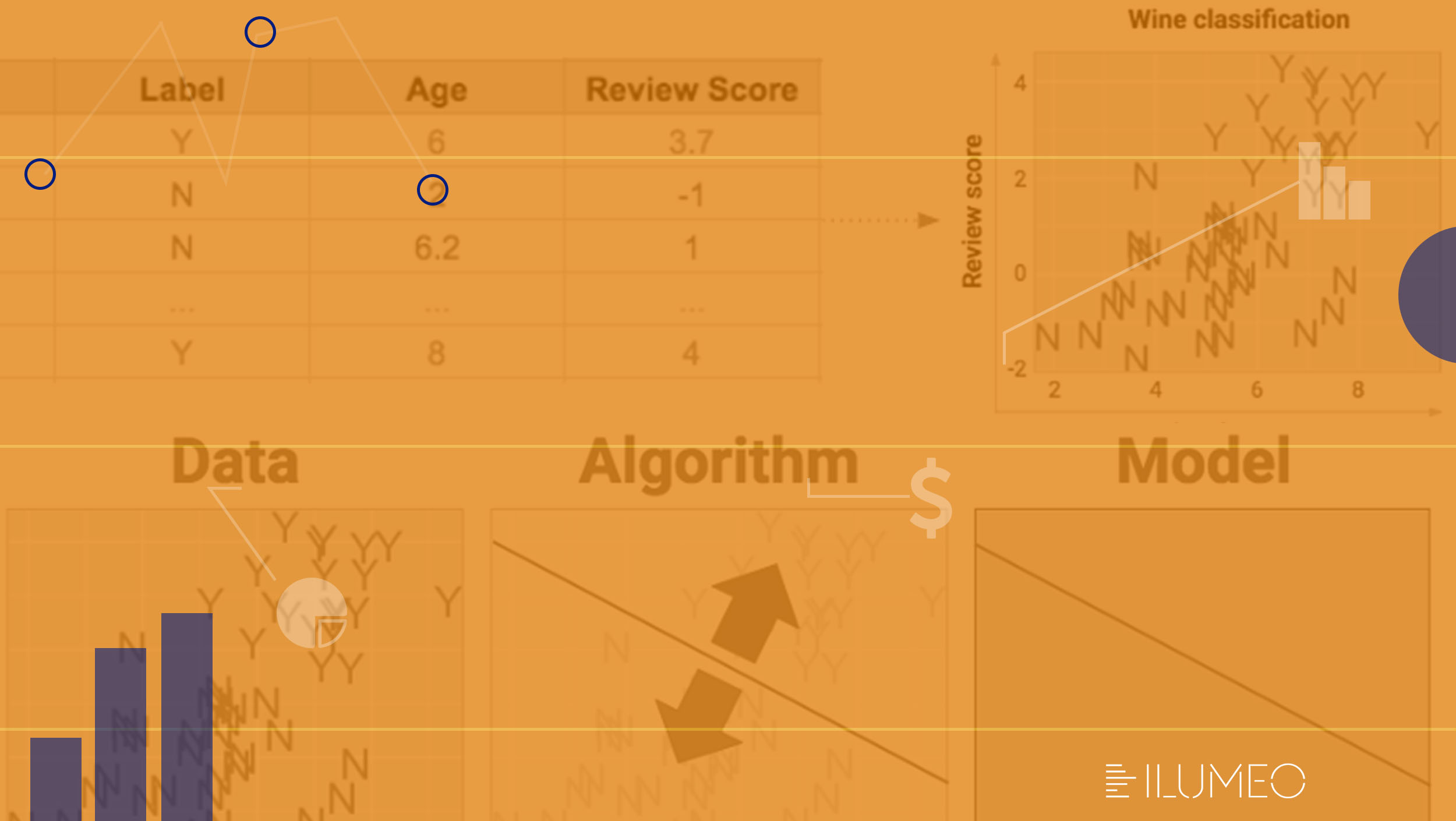
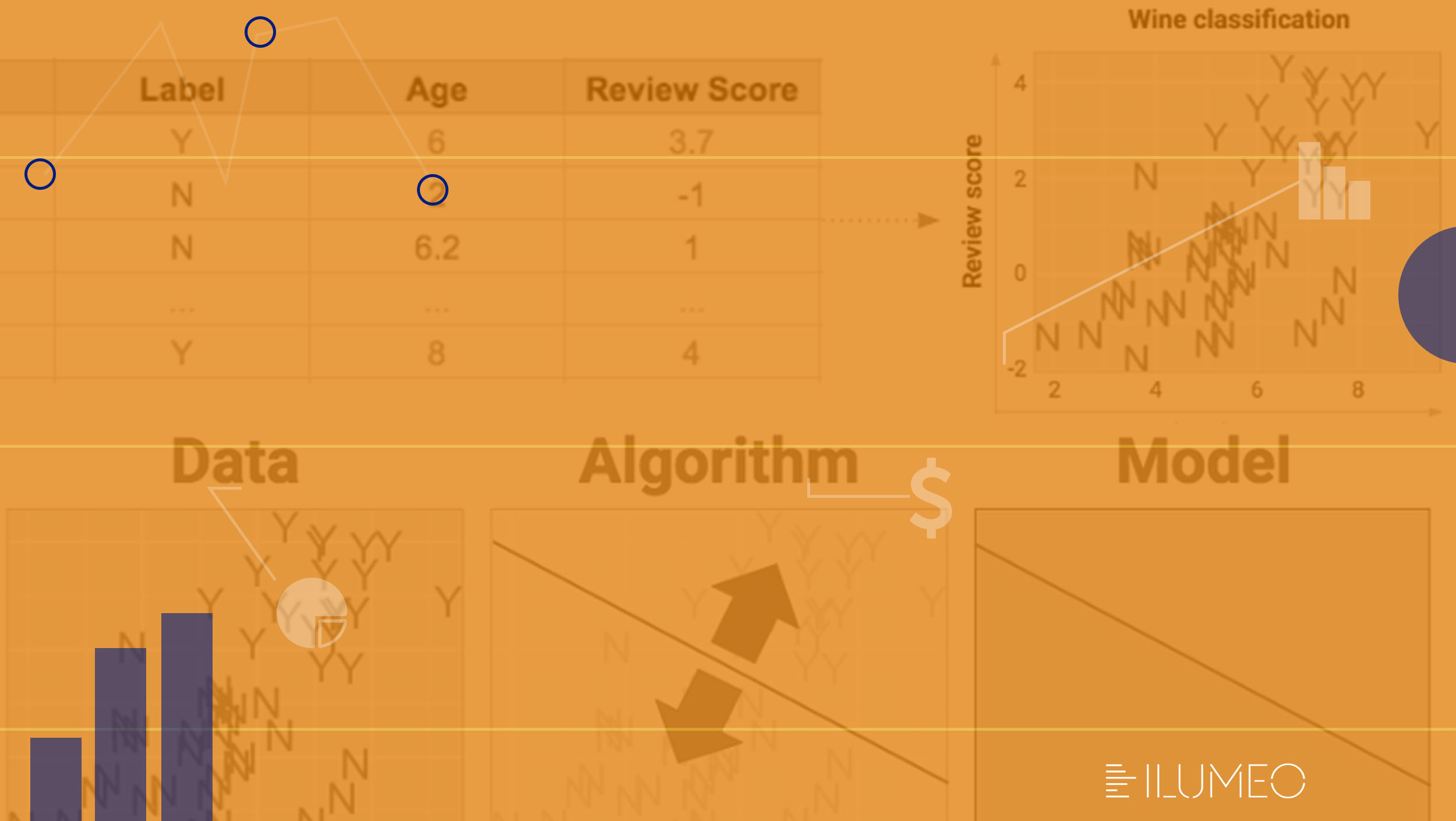
Em primeiro lugar, uma máquina de aprendizado precisa aprender de algum lugar. Ou seja, dados são necessários. Vamos supor que a pesquisadora tenha experimentado 50 tipos de vinho – evidentemente, pelo bem da ciência. Ela tabelou cada vinho segundo um número de identificação (ID), idade (age) e pontuação (review score).
Além disso, cada vinho também recebeu um rótulo (label), que é o campo que receberá aprendizado: Y (“yummy” ou, em português, “gostoso”) e N (“not-so-yummy” ou “não tão gostoso”). Após experimentar e classificar os 50 tipos de vinho, o gráfico a seguir mostra os resultados.

Algoritmo
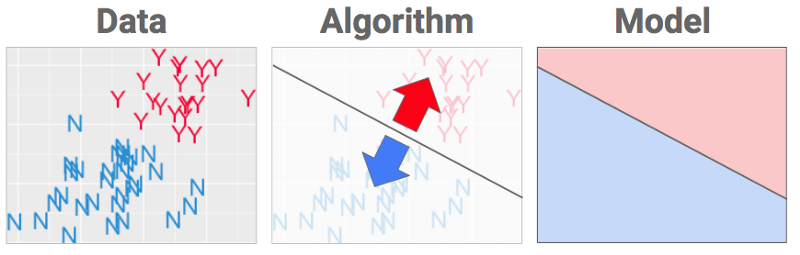
De acordo com Cassie Kozyrkov, escolher um algoritmo de Machine Learning é como escolher a melhor fórmula para separar, no gráfico, os itens vermelhos dos azuis. Como seria a melhor maneira para fazer isso?

Provavelmente você imaginou uma linha divisória entre as diversas letras N e Y. Porém, uma linha horizontal não seria a solução mais adequada. A pesquisadora afirma que o propósito de um algoritmo de Machine Learning é escolher o local mais sensato para colocar uma cerca nos dados. E como é feita essa escolha? Por meio da otimização de uma função objetiva.
Otimização
A função objetiva são as regras do jogo. A otimização é o processo de descobrir como jogar de maneira a ganhar a melhor pontuação. Em Machine Learning, a pontuação é negativa. Colocar um rótulo no lado errado da cerca é uma penalidade e o objetivo é conseguir o mínimo possível desses pontos negativos. Por isso, a função objetiva é chamada “função de perda” (“loss function”) e a meta é minimizar as perdas.
Para jogar, basta observar o gráfico anterior, imaginar uma linha reta e girá-la até obter uma pontuação de zero pontos negativos – ou seja, até que nenhum ponto escape da sua cerca. A solução deve ficar próxima aos gráficos a seguir.

Existe uma variedade enorme de algoritmos. Uma maneira pela qual eles se diferenciam uns dos outros é pelo modo como tentam posições diferentes para estabelecer o limite de separação. Outra variação é o formato da cerca. Ela não precisa ser uma linha reta. Algoritmos diferentes usam diferentes tipos de cerca.

Hoje em dia, aliás, as linhas retas estão em desuso. Cientistas de dados tendem a usar formatos flexíveis e sinuosos, também conhecidos como redes neurais. Por sinal, Cassie faz questão de lembrar que não há uma grande característica neural nessas redes. O nome foi dado como uma aspiração há mais de meio século.
A pesquisadora considera que as comparações entre algoritmos e cérebros humanos são um recurso de marketing. No fim das contas, tudo se trata do formato da cerca que será colocado nos dados. E, na prática, os dados são testados com quantos algoritmos forem possíveis e o pesquisador se atém ao que parece promissor.
Modelo
Uma vez que a cerca está colocada no lugar, o algoritmo completou seu trabalho e o resultado é um modelo. Segundo a pesquisadora do Google, uma palavra chique para “receita”. Agora, o computador recebe algumas instruções para converter os dados em uma decisão, que será efetuada da próxima vez em que uma nova garrafa de vinho for recebida. Se o dado chegar na parte azul, será chamado de azul. Se chegar na parte vermelha, será chamado de vermelho.
Rótulo
No caso do programa sobre vinhos, uma vez que o modelo esteja funcionando a todo vapor, ele é alimentado com dados sobre idade e pontuação. Assim, o sistema identifica a região correspondente e gera um rótulo.

Quando o sistema recebe quatro novas garrafas de vinho, ele combina os dados com as receitas das regiões azul e vermelha e gera um rótulo.
Para conferir se o modelo funciona, os dados de saída (output) são checados. Montes de novos dados são inseridos no sistema e o desempenho é monitorado pelo desenvolvedor.
Modelos de Machine Learning vs programação tradicional
Cassie Kozyrkov salienta que a receita descrita não é muito diferente de um código que um programador escreveria olhando para um problema e criando regras manualmente. Logo, ela suplica: “parem de antropomorfizar máquinas agora”. Um modelo de Machine Learning é, conceitualmente, a mesma coisa que programação tradicional. Algo feito à mão, por seres humanos.
Além disso, ela é crítica a quem considera o retreinamento – o jargão para rodar repetidamente o algoritmo e ajustar o limite na medida em que novos exemplos são reunidos – algo que transforma o programa em uma criatura, algo diferente do produto de trabalho padrão de um programador. Afinal, seres humanos também podem ajustar códigos insistentemente em resposta a novas informações. A pesquisadora provoca: “Se você tem medo de que seu sistema de Machine Learning se atualiza rápido demais, invista em bons testes. Ou aproveite uma boa noite de sono”.
Kozyrkov afirma que o trabalho com Machine Learning é repleto de idas e vindas. Há desafios para ajuste de algoritmos e reparos de códigos. Quando um modelo finalmente é atingido, é possível que ele não responda a novos dados. Por isso, os melhores profissionais para esse trabalho são tolerantes ao fracasso.
Ela conclui dizendo que, quanto antes as pessoas descobrirem que não há mágica ou superstição envolvidas em Machine Learning, melhor. Embora a atividade carregue simplicidade, ela pode realizar feitos incríveis. Segundo a cientista, alavancas também são simples, mas podem mover o mundo.



