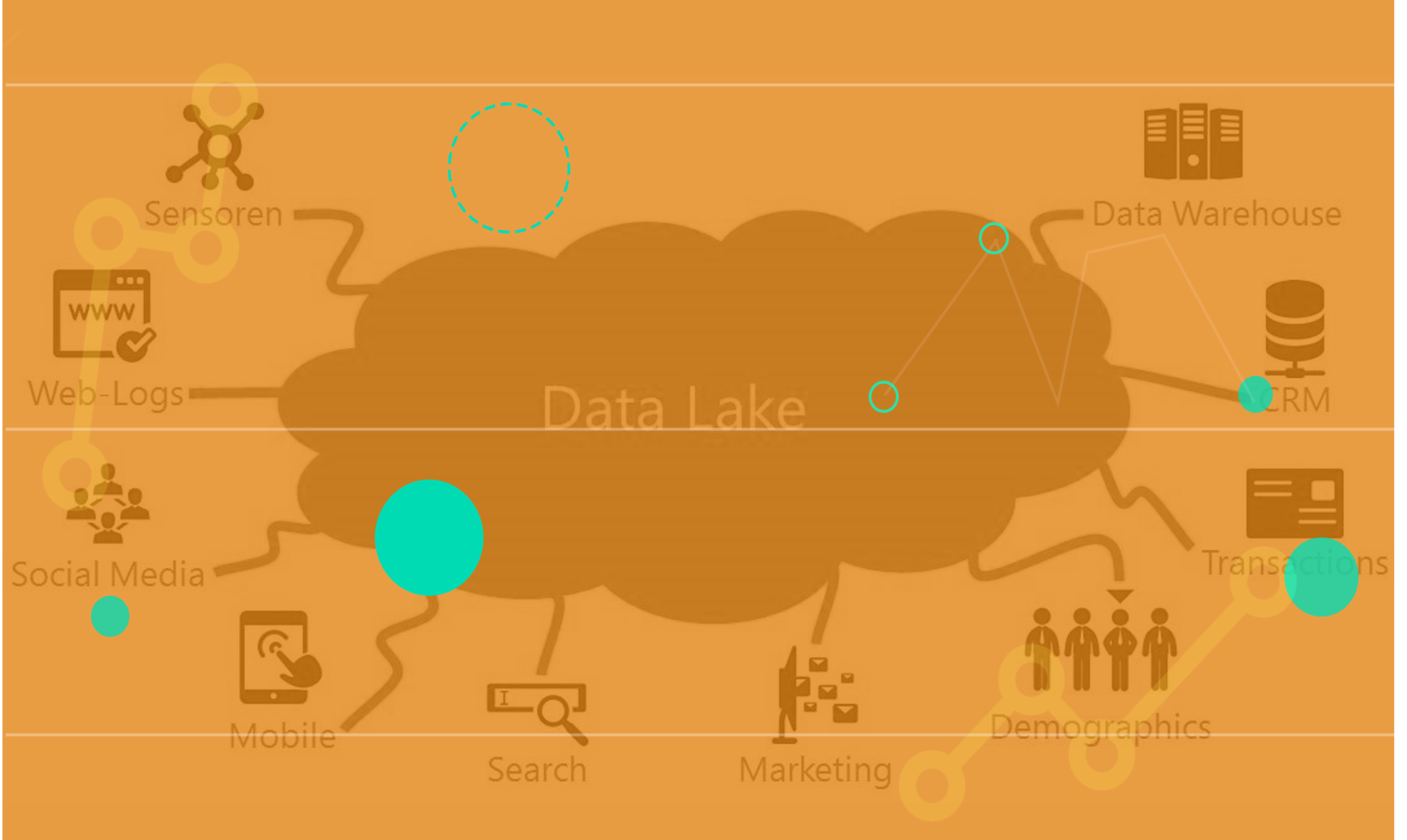
Com os inúmeros dados gerados em uma companhia, seja sobre seus colaboradores, produtos ou clientes, a organização e a análise das informações se tornam ainda mais complexas de se fazer.
Num cenário em que dados são mensurados e chegam de diferentes fontes, formatos e dispositivos, é importante considerar não só o avanço da tecnologia que ajuda na leitura dessas informações, mas também que toda a corporação tenha acesso e se sinta apta e confiante em utilizar essas informações e ferramentas a seu favor. É preciso saber lidar com o volume de dados disponíveis e a velocidade com que eles mudam para gerenciar essa inteligência de negócios e terem uma percepção que traga mais certeza em suas decisões de negócio.
É aí que entram os Data Lakes e a importância de utilizar essa estratégia para fazer uma gestão (armazenamento, processamento e análise) de dados eficiente.
O que são Data Lakes?
Um data lake é um repositório de armazenamento e engine para processamento de grandes volumes de dados. Sua arquitetura permite a manutenção de dados “brutos”, preservando o princípio de imutabilidade, ou seja, os dados não são configurados inicialmente, permanecendo em seu formato nativo e passando por uma reconfiguração somente quando necessário.
Para isso são utilizados bancos de dados relacionais, facilitando o acesso do usuário nas fontes de dados. Afinal, ao serem carregados no seu formato bruto eles podem ser usados para diversos fins e de diferentes maneiras de análise (pensando-se nas variadas técnicas estatísticas e de transformação de dados existentes) e a exploração os dados com mais rapidez e precisão — na criação de correlações, modelagens e obtenção de insights para apoiar a tomada de decisão mais eficiente.
O segredo do Data Lake é o conceito de metadado (dado sobre dado). Cada dado inserido no Data Lake possui um metadado que o identifica e facilita sua localização e posterior análise.
Além disso, à medida em que essa utilização vai sendo compreendida e desenvolvida, a análise pode vir a ser cada vez mais segmentada (para entender, por exemplos, indicadores de diferentes produtos, pontos de venda, lotes de lançamento, equipes, áreas da empresa, etc.). Isso permite que os líderes e membros em geral da organização possam, em algum momento da “jornada” de implementação, vir a gerar relatórios de dados por si próprios.

Fonte: Estrutura/Lógica de um Data Lake — Databricks
Por que você precisa de um Data Lake?
Desde o final dos anos 80, a tecnologia warehouse e as arquiteturas MPP fizeram com que os sistemas aumentassem sua capacidade de lidar com tamanho de dados maiores. No entanto, enquanto os warehouses eram ótimos para dados estruturados (dados organizados e representados com uma estrutura rígida, que tenha sido previamente planejada para armazená-los — como linhas e colunas que identificam informações sobre as unidades de análise, como uma planilha de Excel), muitas empresas modernas precisam agora lidar com dados não estruturados (dados advindos de diversas fontes e em diversos formatos, tais como textos, vídeos, imagens, áudios, mensurações em diferentes escalas, etc.) e com alta variedade, velocidade e volume.
Para resolver essa questão, os arquitetos começaram a imaginar um sistema único para abrigar dados de muitos processos e fontes analíticas diferentes, começando a construir data lakes, os repositórios de dados brutos em vários formatos. Com essa plataforma é possível implementar estruturas de dados e recursos de gerenciamento de dados semelhantes aos de um data warehouse, diretamente no tipo de armazenamento de baixo custo usado para data lakes.
Alguns dos benefícios de utilizar data lakes são a capacidade de análise de integridade dos dados, com mecanismos robustos de auditoria, utilização de ferramentas de BI nos dados brutos, organização dos dados em clusters, possibilidade de integração com API e ferramentas de machine learning e criação de relatórios em tempo real.
Cabe aqui realçar que, numa comparação com os data warehouses, pode-se dizer que o data lake é o repositório para quem precisa abrigar qualquer tipo de dados em qualquer escala. Dashboards, dados em tempo real, analytics, planilhas, informações de machine learning… enfim. Não há restrições para a ferramenta, nem exigência de tratamento prévio dos dados. Já o data warehouse, é um espaço preparado para receber dados tratados e padronizados (dados estruturados). Assim, para inserir e armazenar qualquer informação em um DW, é fundamental que elas tenham passado pelo processo de tratamento, diferentemente dos data lakes.
Quais são os estágios de maturidade?
Pensando em implementar um data lake em uma empresa ou qualquer tipo de organização, é bom ter em mente que existem pelo menos quatro grandes estágios de maturidade.
Landing zone ou raw data
Nesse primeiro nível, o Data Lake serve como um ambiente de captura de dados, agindo como uma pequena camada de gerenciamento de dados — incluindo governança e classificação rigorosa — que permite armazenamento antes destes serem preparados para implementação no ambiente de computação.
Sendo construídos separadamente sistema central de TI, os dados internos (produção, estoque, vendas, etc.) podem passar a ser complementados com fontes externas de dados (informações públicas — IBGE, DataSus, dados econômicos, indicadores de empresas privadas, webscraping, pesquisas de clima, etc.).
Numa empresa de e-commerce, por exemplo, este é o nível em que se reúne todos os tipos de dados que a organização possa ter (leads que chegam no carrinho de compras, vendas de cada produto nos últimos meses, logins na página de vendas, engajamento nas redes sociais, pesquisa de satisfação com os consumidores, peças em estoques distribuídos pelas regiões do país, etc.).
Data Science Environment
No segundo estágio, o acesso aos dados é fácil e mais rápido e, assim, é possível usar mais ativamente o Data Lake como uma plataforma para se conduzir experimentos. O tempo e esforço que cientistas e analistas usavam antes para inserir e organizar os dados, podem dedicar a desenvolver análise exploratórias e avançadas.
Esta é a fase em que passa então a ser possível executar e analisar os dados como insumos de fato para projetos de ciência de dados; realizando desde simples análises de cluster até o desenvolvimento de protótipos de programas (dashboards, códigos, alimentadores, etc.) analíticos.
Seguindo no exemplo do e-commerce, aqui passa a ser possível, por exemplo, realizar análises exploratórias e avançadas sobre as estratégias de vendas, bem como começar a se construir painéis de acompanhamento de resultados de eventuais testes A/B (no lançamento de promoções, no preço de venda de determinados produtos, etc.) para gestores comerciais e equipes de marketing.
Offload for Data Warehouses
Nesse nível, além das ações descritas nos dois anteriores, é possível integrar os data lakes com os data warehouses existentes, colocando dados aparentemente frios (aqueles que são raramente utilizados ou estão inativos, e que ficavam fora do data warehouse por falta de espaço ou tratamento) no armazenamento e em “análise”; para que possam ser usados na geração de insights sem exceder o limite de armazenamento.
Pensando mais uma vez no caso de um e-commerce, pode-se aqui inserir no data lake dados como cliques em determinado item da página, comentários recebidos nas redes sociais, avaliações no Reclame aqui, ou outros que pudessem acabar ficando de certa forma “esquecidos” (frios, deixados de lado), por demandar tratamento e espaço para sua inserção no data warehouse. Muitas vezes esses dados podem vir a trazer insights que antes não eram possíveis de serem acessados.
Critical component of data operations
No último estágio as informações da empresa já estão totalmente integradas ao Data Lake, essa plataforma se torna parte essencial da infraestrutura de dados.
Neste quarto estágio é possível criar aplicativos de uso intensivo, como um painel de gerenciamento de desempenho, ou combinar insights obtidos pelo Data Lake com insights de outros aplicativos. O data lake permite agora que a organização caminhe rumo a um cenário de “data-as-a-service” — contexto no qual os dados são acessíveis a diversos níveis de maturidade e envolvimento de colaboradores, além de serem possíveis análises customizadas e automatizadas (com constantes otimizações, ajustes e melhorias, claro).
Por fim, aqui seria então a fase em que o data lake de um e-commerce pode se conectar, por exemplo, a ferramentas de automação, a um software de CRM, a uma aplicação (app) de otimização de compra de novos produtos para estoque, etc. — afinal, aqui o data lake está tão avançado que permite que os engenheiros, cientistas e analistas de dados executem integrações junto a aplicações externas.
Mas, cabe refletir…
O processo de implementação ou aprimoramento data lakes, como um todo, traz desafios e pontos de atenção.
O primeiro é que estruturar um data lake não é tarefa fácil — muito pelo contrário. Em geral, as empresas mensuram e tratam seus dados de forma dispersa e sem parametrização, fazendo com que esse processo de centralização dos dados acabe, muitas vezes, sendo demorado e complexo.
O segundo é que atualmente todo mundo quer pensar em ter um data lake, muitas vezes por um “modismo” ou “fetiche” por controle e/ou organização — pela sensação de saber que está tudo lá disponível. Por isso, num processo de desenho da implementação de data lakes (ou para se decidir o que será feito com os dados já em armazenamento ou processamento), é preciso criar objetivos e pontos de partida, examinando a variedade e tamanho dos dados e a finalidade geral desta empreitada.
Uma terceira questão é que todo esse processo (de implementação e gestão de data lakes) exige uma governança e compliance, porque tanto a coleta/armazenamento quanto o acesso interno aos dados precisam seguir regras — sejam elas de códigos de ética corporativos (dependendo do setor da empresa), de um regimento interno, ou leis de âmbio nacional e internacional (como o LGPD e o GDPR).
Por fim, vale ainda destacar a importância do conhecimento e capacitação do time para a aplicação dos dados e informações na inteligência comercial. Alfabetização de dados (data literacy) são essenciais nesse processo.


