
Neste artigo, apresentamos a definição de Data Science, falamos sobre o perfil do cientista de dados, discutimos o contexto atual da área e suas relações com Inteligência Artificial e Machine Learning.
O que é Data Science?
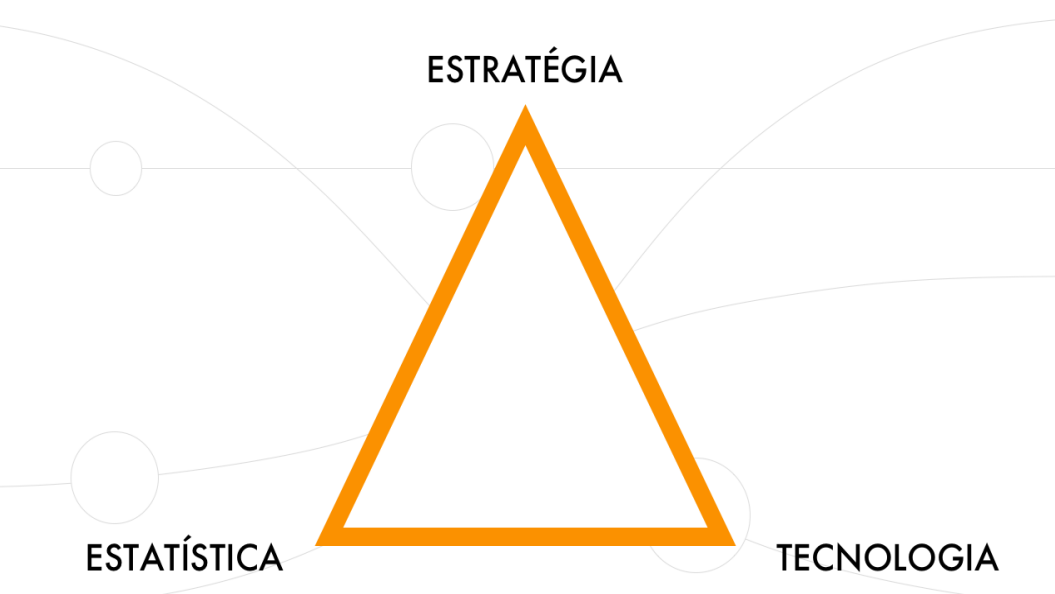
Não existe uma definição cravada a respeito do que é Data Science – ou ciência dos dados. Autores diferentes cercam o assunto de maneiras diferentes, tal como acontece, por exemplo, com o termo “engajamento”. Porém, um apanhado geral do que é discutido nos grandes centros de pesquisa sobre o assunto nos leva à definição de que Data Science é uma intersecção entre estratégia, estatística e tecnologia.
Quando traçamos tecnologia como um dos pilares desse campo de estudos, não é só por causa das inúmeras ferramentas utilizadas na análise de dados. Mais do que isso, a Data Science depende intrinsecamente de uma lógica tecnológica.
Uma das bases da programação é a lógica de IF > THEN. Em português, SE > ENTÃO. Essa é uma função tradicional em aplicações computacionais. Ela implica que SE tal condição for verdadeira ou falsa, ENTÃO determinado comando será executado. Por exemplo, ao usar um software de processamento de texto como o Word, SE o usuário pressionar a barra de espaço no teclado, ENTÃO o monitor acrescentará um espaço no parágrafo.
Data Science se utiliza da mesma lógica para resolver um problema. Vamos ilustrar com um exemplo de como seria a aplicação de Data Science para diminuir a ocorrência de crimes. Em primeiro lugar, é feita uma decisão de estratégia: qual crime enfrentar? Em nosso exemplo, vamos diminuir o número de assaltos a lojas de conveniência.
Nesse caso, a estatística nos diz quais são os sinais comportamentais que são preditivos dos assaltos. O indivíduo entrou na loja de capacete? Durante o dia ou à noite? A loja está vazia ou cheia de clientes? Ou seja, são aferidos dados estatisticamente calculáveis. Esses dados podem se tornar meros relatórios que serão apresentados para um secretário de segurança – e nesse caso, não alcançam a lógica de Data Science.
Porém, esses dados também podem se tornar acionáveis. SE foi identificado determinado padrão, ENTÃO determinada ação será tomada para atingir o resultado traçado a partir da estratégia. Quando é utilizada a lógica de IF > THEN a partir dos padrões identificados é que estamos trabalhando com Data Science.
Logo, fica claro que a lógica de Data Science se contrapõe à lógica da pesquisa tradicional. Esta se limita a apresentar dados em relatórios, nos quais as “recomendações a partir da pesquisa” são reveladas em um slide final. Já a Data Science tem o objetivo final de ser executável: ou seja, definir qual ação será tomada após a identificação de um padrão.
Resumidamente, Data Science é uma lógica de utilização de técnicas estatísticas multivariadas cujo output não só um relatório e/ou diagnóstico, mas a entrega acionável para operação. Ela serve para otimizar continuamente os resultados e, assim, reduzir riscos como desperdício ou perda de oportunidades.
Quem é o profissional de Data Science?
O data scientist – ou cientista de dados – por excelência é o profissional que apresenta domínio dos três vértices do triângulo mencionado: estatística, tecnologia e estratégia. Ou seja, ele tem conhecimento profundo de técnicas estatísticas capazes de modelar e resolver problemas, tais como análise de variância, análise de cluster, árvore de decisão, redes neurais, séries temporais e regressões.
Além disso, ele entende de tecnologia. Analisa dados via SQL e SPSS, visualiza dados via Power BI e Tableau, programa em linguagens especializadas em análises estatísticas, como Python e R.
No entanto, esse profissional não fica restrito aos ambientes da tecnologia e da estatística. Ele também sabe pensar em termos de negócios, problematizar os desafios, definir estratégias e diagnósticos. Ou seja, domina conceitos como geração de leads, gestão de marcas, mix de produtos, pricing, churn, score de prospects, previsão de demanda e estoque.

Não é preciso dizer que esse profissional é difícil de ser encontrado. Para empresas que buscam uma abordagem de Data Science, uma resposta muito mais factível e adequada à realidade atual reside na integração de diferentes equipes. Ou seja, ao invés de isolar profissionais de tecnologia em seus departamentos, integrá-los de vez aos negócios.
Assim, mais do que desenvolver todas as habilidades de um cientista de dados, profissionais de marketing e executivos precisam desenvolver um pensamento capaz de desenhar projetos de Data Science. Esses profissionais precisam de repertório para conseguir liderar e dialogar com os especialistas das áreas técnicas.
Qual é o contexto atual da Data Science?
Os profissionais que já atuam no mercado como data scientists, em geral, são detentores de altos salários e atuantes no departamento de TI. Logo, profissionais focados em técnica, mas não necessariamente em liderança – e não falamos no sentido motivacional, nas no sentido de liderança de projeto. Além disso, uma vez que esses cientistas ficam restritos ao ambiente do TI, tendem a ter pouco entendimento de negócios.
Ciência
Esse profissional só nasce depois de muito estudo. E, a rigor, o estudo sistemático é realizado dentro da pesquisa acadêmica. Porém, no Brasil há uma separação entre academia e mercado. Não é preciso dizer que essa desconexão é pouco saudável e impede o nosso crescimento. Afinal, hoje em dia, as maiores empresas do mundo nasceram dentro da universidade.
No entanto, quem tenta vencer essa barreira se depara com outros desafios. Os artigos científicos internacionais são publicados em vasta quantidade, o que torna difícil acompanhar todos os estudos recentes. Além disso, grande parte dos artigos é árida e direcionada para especialistas do assunto. Por fim, a academia às vezes se fecha em campos de estudos específicos e não pratica a interdisciplinaridade exigida pela Data Science.
Empresas
Em nosso atual contexto, a Data Science tende a andar mais rápido em bancos e seguradoras. Essas empresas têm uma tradição maior na análise de dados e têm mais recursos para os investimentos necessários. Da mesma maneira, o setor de serviços tende a caminhar mais rápido do que o setor de produtos, conforme o gráfico a seguir.

Uma característica delicada do mercado é ser pautado por fornecedores. Ao invés de desenhar os problemas estrategicamente, é comum a figura do gestor que meramente ordena a compra de um software de última geração – como se ele fosse capaz de resolver os problemas por si só.
Por fim, o setor empresarial às vezes demora a absorver novas lógicas de mercado. Por exemplo, talvez outras categorias de serviços possam utilizar a proposta de preço dinâmico praticada pelo Uber.
Inteligência Artificial vs Machine Learning
Em um trabalho estatístico tradicional, após a coleta e análise dos dados, um ser humano é responsável pela decisão tomada a partir dos resultados. Já o conceito de Inteligência Artificial prevê que a decisão seja tomada pela máquina – isso, aliás, traz à tona diversas questões éticas em relação à utilização de IA. Por exemplo, a responsabilidade por erros da máquina é de quem criou o algoritmo? Ou de quem o contratou?
Machine Learning é uma área de Inteligência Artificial na qual é possível criar algoritmos para ensinar uma determinada máquina a desempenhar uma tarefa. O ponto marcante dessa definição é a capacidade que a máquina tem de aprender. O consagrado psicólogo Piaget afirmava que a inteligência é uma organização mental que tem a finalidade de adaptar-se ao meio. Da mesma maneira, o modelo de Machine Learning tem o objetivo de adaptar-se à informação nova, tal como pode ser visto no vídeo a seguir.
Logo, não é porque tal termo está em voga que todo projeto de análise estatística – que visa diagnóstico e tomada de decisão – precisa ser necessariamente de Machine Learning. Essa opção só faz sentido quando existe a necessidade de adaptar-se ao dado novo.
Por exemplo, como faz a Netflix. A empresa exibe capas diferentes e recomenda programas segundo os padrões de comportamento de cada espectador: o tempo empreendido em cada série, o engajamento provocado por cada programa, o comportamento de usuários similares etc. Todos esses dados são novas informações que são absorvidas e geram decisões: quais capas serão exibidas e quais programas serão recomendados para cada espectador.
A mesma lógica é empreendida no Uber, quando o aplicativo de transporte decide o valor de corrida segundo bairro, preço do concorrente e demanda por carros. Essas decisões são automatizadas via Machine Learning e, mais do que isso, em tempo real.
Atualmente, empresas evitam até mesmo processos judiciais por meio dessa tecnologia. Quando um consumidor telefona no call center para reclamar sobre determinado serviço, o tema da reclamação, o tom da voz e até o padrão de comportamento das comarcas de determinada região do país podem ser usados como dados para orientar a ação do atendente.
Para saber mais
Tudo o que foi descrito neste artigo foi apresentado no curso Data Lab – Entendendo a Ciência por Trás dos Dados, uma parceria entre a Ilumeo e a Sandbox. O curso aborda o repertório técnico sobre Data Science que o estrategista de negócios precisa dominar. O programa foi formado a partir de conversas com CEOs e CMOs, com o intuito de formar profissionais que saibam enxergar, briefar, entender e criticar projetos analíticos de Data Science.
A próxima edição começa em 15 de abril de 2019. Inscreva-se!


