
Veja como a ciência de dados pode contribuir para automatizar e melhorar os processos financeiros neste setor.
Analisar o crédito de um cliente consiste, basicamente, em verificar se ele realmente tem condições de honrar o compromisso assumido. O objetivo é identificar o perfil e as condições financeiras do cliente, a partir de suas informações básicas e de seus dados financeiros. Assim, a empresa também define um valor mínimo de compra, a taxa de juros aplicada e o prazo de pagamento das parcelas, por exemplo. De forma geral, é uma forma de evitar inadimplência nas operações de crédito.
Essa análise pode ser realizada tanto para clientes pessoa física quanto jurídica e é hoje um dos maiores campos de atuação da ciência de dados aplicada ao setor financeiro. Afinal, a avaliação manual dos pedidos de empréstimo e das informações do cliente apresenta um risco iminente. A habilidade dos avaliadores humanos sempre será limitada em termos de precisão e velocidade. Logo, a utilização de métodos e ferramentas para automatizar e escalar esses processos ajuda a aumentar as chances de emissão de empréstimos de risco com menor probabilidade de inadimplência.
Os problemas dos dados
Para fornecer empréstimos, por exemplo, as empresas podem enfrentar alguns problemas relacionados à concessão de crédito e praticamente todos eles têm a ver com o perfil do cliente, verificado a partir dos dados que as instituições financeiras têm sobre ele. E a realidade é que nem sempre eles são suficientes para a análise. A ideia de dados insuficientes em um mundo tão digital pode até parecer estranha, mas é real, principalmente pela falha em conseguir acessá-los.
Além do acesso aos dados disponíveis, sejam eles estruturados ou não estruturados, a análise é o ponto essencial para o processo de avaliação do risco de crédito. A criação de grupos relativamente pequenos para entender o comportamento geral do cliente desempenha um papel importante nessa avaliação.
Automatizando a análise de crédito
É necessário adotar métodos inovadores, que subsidiem uma tomada de decisão acertada para negócios de todos os portes e segmentos de atuação.
Por isso, é necessário usar algumas ferramentas que ajudam a analisar a concessão de crédito. Entre as tecnologias necessárias estão:
Business Intelligence (BI): coleta e processa um grande volume de informações para gerar estatísticas confiáveis e determinar se a venda a prazo é uma boa ideia naquele contexto. Garante agilidade e ajuda a identificar os riscos da operação;
Machine Learning: automatiza a análise de dados e os modelos analíticos para conceder a venda a prazo de modo mais seguro. Há o aprendizado autônomo, conforme os comandos oferecidos, o que aumenta a precisão da avaliação;
Big Data: usa diferentes fontes para coletar dados e oferecer informações valiosas, que trazem exatidão para a análise de crédito.
Todas essas abordagens se beneficiam muito do processo de automação. Eles reúnem informações sobre os clientes, traçam os perfis e gerenciam os riscos das operações. A partir do uso das soluções, há mais agilidade no processo de análise e maior potencial de fidelização dos clientes. Da mesma forma, a avaliação do crédito se torna mais precisa e você protege sua empresa contra desequilíbrios financeiros.
Um caso de Machine Learning na avaliação de risco de crédito
O aprendizado de máquina permite a automação do trabalho de análise de crédito. Os algoritmos têm muito a oferecer ao mundo da avaliação de risco de devido ao seu poder preditivo e alta velocidade. A cientista de dados Sarah Beshr escreveu artigo no Medium sobre como usar machine learning para prever a probabilidade de um tomador de empréstimo ficar inadimplente.
O conjunto de dados utilizados pode ser encontrado no Kaggle e contém dados de 32.581 mutuários e 11 variáveis relacionadas a cada mutuário. São variáveis como:
Idade – variável numérica; idade em anos
Renda – variável numérica; renda anual em dólares
Situação de residência – variável categórica; “aluguel”, “hipoteca” ou “próprio”
Intenção de empréstimo – variável categórica; “educação”, “médico”, “empreendimento”, “reforma da casa”, “pessoal” ou “consolidação de dívidas”
Montante do empréstimo – variável numérica; valor do empréstimo em dólare
Grau do empréstimo – variável categórica; “A”, “B”, “C”, “D”, “E”, “F” ou “G”
Racional entre o empréstimo e o rendimento – variável numérica; entre 0 e 1
Padrão histórico – variável binária, categórica; “S” ou “N”
Status do empréstimo – binário, variável numérica; 0 (sem padrão) ou 1 (padrão) → esta será a variável de destino
Após saber os tipos de variáveis disponíveis, o próximo passo é a etapa de exploração e pré-processamento de dados. Verifica-se se há variáveis ausentes ou com erro e outliers, para que possam ser corrigidos.
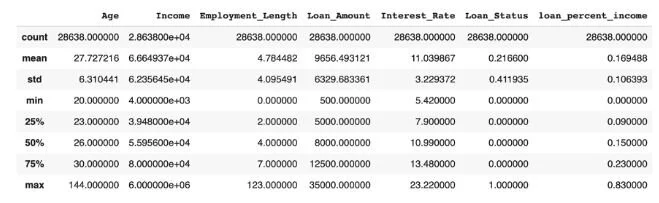
Representação do conjunto de dados
O conjunto de dados pode apontar inconstâncias, como idade de 144 anos ou pessoas que estiveram empregadas por 123 anos. Deixando de lado, os valores discrepantes das variáveis idade e tempo de emprego podem afetar negativamente o modelo e, portanto, devem ser removidos.
Após o processo finalizado e com os dados limpos em mão, convém explorar mais a fundo como o status do empréstimo está relacionado a outras variáveis no conjunto de dados.

Podemos ver que aqueles que não apontam inadimplência têm um valor médio de índice de empréstimo / receita mais baixo em todas as classes de empréstimos. Também podemos ver que nenhum tomador de empréstimo com grau de empréstimo G foi capaz de honrar o empréstimo.
Usando um diagrama de categoria paralelo é possível entender como diferentes variáveis categóricas do nosso conjunto de dados estão relacionadas entre si e podemos mapear essas relações com base no status do empréstimo.

Principais conclusões do diagrama:
O conjunto de dados é composto principalmente de clientes que nunca entraram em inadimplência em um empréstimo;
As notas “A” e “B” do empréstimo são as mais comuns, enquanto “F” e “G” são as menos comuns;
Os locatários de casas ficam inadimplentes com mais frequência em seus empréstimos do que aqueles com hipotecas, enquanto os proprietários de casas tendem a ficar menos inadimplentes;
Os clientes contrataram menos empréstimos para reforma da casa e mais para educação. Além disso, a inadimplência era mais comum em empréstimos contraídos para cobrir despesas médicas e consolidação de dívidas.
Tudo pronto para a próxima etapa: treinamento e avaliação do modelo.
Serão treinados e testados três modelos, KNN, regressão logística e XGBoost. Também será avaliado seu desempenho na previsão de inadimplências de empréstimos e sua probabilidade.

Em primeiro lugar, precision dá a proporção de verdadeiros positivos para o total de positivos previstos por um classificador, onde positivos denotam casos padrão no contexto. Dado que eles são a classe minoritária no conjunto de dados, podemos ver que os modelos fazem um bom trabalho em prever corretamente essas instâncias menores. Além disso, Recall, também conhecido como taxa positiva verdadeira, nos dá o número de reais positivos dividido pelo número total de elementos que realmente pertencem à classe positiva.
Neste caso, o Recall é uma métrica mais importante do que a Precisão, visto que estamos mais preocupados com falsos negativos (o modelo prevendo que alguém não ficará inadimplente, mas ele fica) do que falsos positivos (o modelo prevendo que alguém ficará inadimplente mas ele não fica).
Por último, F1 Score fornece uma pontuação única para medir a precisão e a recuperação. Agora que sabemos o que procurar, podemos ver claramente que o XGboost tem o melhor desempenho em todas as 3 métricas. Embora tenha pontuado melhor em Precision em oposição a Recall, ainda tem uma pontuação de F1 muito boa de 0,81.
Por último, é hora de identificar quais recursos foram mais influentes na previsão da variável-alvo.

Podemos ver na figura acima que o aluguel, o índice empréstimo / receita e o empréstimo grau C são as três características mais importantes para prever a inadimplência do empréstimo e sua probabilidade.
De forma resumida, o passo a passo apresentado aqui mostra que os dados foram pré-processados e treinados, avaliando-se os resultados de 3 modelos de machine learning por sua capacidade de prever inadimplências de empréstimos e sua probabilidade. Depois de identificar que o XGBoost teve o melhor desempenho em todas as métricas, investiga-se quais recursos eram mais importantes para as previsões
Assim, é possível completar a demonstração de como o aprendizado de máquina pode ser aplicado ao mundo da avaliação de risco de crédito, automatizando e tornando o processo muito mais assertivo e preciso.


