

Conseguir novos clientes é até 25 vezes mais caro do que manter um antigo; veja como a Data Science pode ajudar na retenção de clientes
A cada dia, se torna mais evidente o valor que existe no processamento e análise de dados para qualquer empresa. E é nesse momento que os cientistas de dados entram em cena, extraindo informações que auxiliem a organização a tomar melhores decisões de negócios, diminuir prejuízos e aumentar a produtividade, e em muitos casos fazer a retenção de clientes. Neste artigo, vamos nos concentrar nesse último tópico. Afinal, a fidelidade de um cliente é uma questão importante para qualquer empresa, e a ciência de dados tem uma série de ferramentas para ajudar nessa retenção.
De acordo com um estudo da Frost & Sullivan com a NICE Latin America, 95% dos clientes concordam que a experiência é fundamental para definir sua lealdade a uma marca. O levantamento também mostra que conquistar um consumidor pode ser até 25 vezes mais caro do que manter um já existente. Vamos ver um pouco mais na prática como Data Science pode ajudar nesse processo de retenção, a partir do case do Mercado Livre, publicado na página Mercadolibre Tech, criada para que membros da equipe de tecnologia da empresa pudessem compartilhar conhecimentos de forma pública..
Mercado Livre: um estudo sobre retenção de clientes
Neste artigo, Pedro Zenone, Data Science Lead do Mercado Livre, explica alguns dos problemas de retenção de clientes vividos pela empresa, e como a Ciência de Dados ajudou a encontrar soluções melhores.
Segundo ele, como parte do ciclo de vida dos clientes, a ideia é que os usuários que demonstrem um bom comportamento de compra no passado, se mantenham ao longo do tempo. Para promover esse comportamento, a empresa desenvolve um modelo preditivo, que permite tomar ações precoces sobre usuários valiosos que estão perto de reduzir drasticamente seu valor de tempo de vida futuro (chamado de LTV).
Contudo, medir o aumento gerado no negócio no longo prazo pode ser algo complexo, uma vez que os efeitos se diluem ao longo do tempo. Por isso, era necessário aplicar técnicas para inferir o efeito causal.
Entendendo o problema
Primeiro, porém, é preciso entender mais sobre o problema da retenção de clientes no Mercado Livre. Afinal, ele é hoje o mais importante e-commerce da América Latina, então quais seriam suas dificuldades neste aspecto?
Segundo Pedro Zenone, ao organizar uma grade entre compras contínuas e discretas, e configurações contratuais e não contratuais, percebeu-se que o Mercado Livre é o tipo de compra não contratual e contínua. Isso porque a compra pode ser a qualquer momento, então não há um conceito de contrato estabelecido. O que nos leva ao primeiro problema: não há garantias de que o usuário comprará novamente.
O segundo problema é que, caso volte a comprar, a empresa não sabe quantas vezes esse comportamento vai se repetir. E o pior: a natureza de todas as compras de comércio eletrônico é determinada por uma forte distribuição exponencial; ou seja, muitos usuários compram pouco, e poucos compram muito.

Com isso em mente, a empresa precisava prever se o usuário reduziria sua frequência de compra, para tomar uma atitude preventiva e evitar a perda de engajamento. Para isso, desenvolveu a seguinte estratégia:

Primeiramente, os usuários são injetados em uma estrutura de previsão de “perda de engajamento” (ou relacionamento com a marca). Em seguida, aqueles com probabilidade suficiente para realizar uma ação são estimulados por meio de uma notificação, com um benefício de cupom de desconto inteligente no aplicativo. Depois, passa-se ao estágio de inferência causal para medir o efeito do estímulo. Aqui, a ideia era quantificar a retenção e o crescimento na frequência de compra dos usuários, medindo o impacto acumulado ao longo do tempo.
Por fim, os KPI’s seguidos pela empresa serão a frequência e a receita incremental no longo prazo. Isso permitirá responder a perguntas como:
– Qual é o valor de um comprador que conseguimos reter?
– Quantas vezes mais eles comprarão de forma incremental?
– Qual é o lucro líquido que esta ação nos permite gerar?
Respostas muito importantes para qualquer tipo de negócio.
Medindo os dados
Agora que o problema está mais claro, é o momento de realizar a medição dos dados. No caso do Mercado Livre, a medição do efeito causal gerado foi pensada como a diferença entre os usuários que foram estimulados e os que não foram estimulados. Assim, em termos técnicos, seria:
-
Usuários estimulados: grupo de teste;
-
Usuários não estimulados: grupo de controle;
-
Estímulo: tratamento;
-
Efeito gerado: resultado. S (1): resultado quando o usuário recebe o tratamento. S (0): resultado quando o usuário não recebe o tratamento.
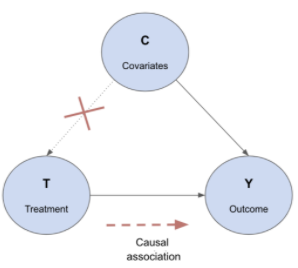
Importante dizer que o caminho para a inferência causal requer uma compreensão conceitual do problema enfrentado, e das condições disponíveis. Somente assim é possível delinear os principais problemas a serem enfrentados se possuir um grupo de controle à disposição.

No caso do exemplo acima, a linha pontilhada indica quando não há um grupo de controle disponível; porém, para esse tipo de estudo, existem outras técnicas potencialmente aplicáveis, como impacto causal ou controle sintético.
No caso do Mercado Livre, a escolha dos grupos aleatoriamente garantiu que todas as co-variáveis antes do estímulo sejam mantidas nas mesmas proporções, tanto para os grupos de teste quanto para os de controle. Nesse caso, a empresa manteve a mesma proporção de usuários Android / IOS, visitantes / não visitantes, desistentes de checkout, etc. Ou seja, não há co-variável que determine a qual grupo o usuário pertence.
Variáveis Instrumentais (IV)
Em seguida, foram analisadas as variáveis instrumentais. Este será o ponto de inflexão para justificar o que será analisado nos próximos pontos. No caso do Mercado Livre, as notificações push enviadas para o aplicativo possuem várias etapas, pois a pessoa pode receber o push, ver, abrir e comprar. Ou seja, a ideia era medir o efeito sobre quem foi realmente estimulado, pois o estímulo deve mudar o comportamento de compra com o tempo.
Nesse caso, foi utilizado o método denominado Variável Instrumental (IV), que permitiu à equipe do Mercado Livre calcular o efeito incremental em relação a quem recebeu o estímulo. Este efeito é denominado Complier Average Causal Effect (CACE), conforme abaixo:
CACE = E [Y (Z = 1) – Y (Z = 0) | T (Z = 1) = 1, T (Z = 0) = 0]
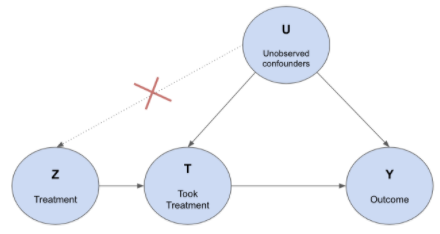
Como é possível conferir no gráfico de causalidade acima, ele descreve as relações causais entre a variável instrumental (a atribuição aos grupos de teste e controle é aleatória) que determina quem pode acabar recebendo o estímulo (se Z = 0, então T = 0). Com isso, o tratamento depende de variáveis externas, como a opção de exclusão do usuário em caso de conexão ruim com a internet, por exemplo.
Nesse caso, um dos métodos para medir o CACE é por meio da técnica 2SLS, composta de duas etapas: primeiro, estima-se T = f (Z) para quebrar o elo entre U e T; então, estima-se Y = f (T), uma vez que T não está relacionado a U.
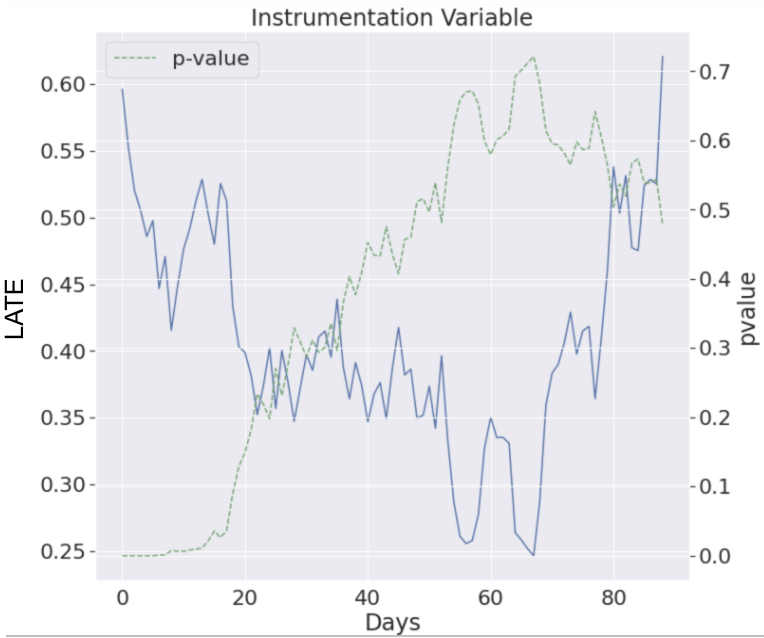
No fim, quando tudo é posto em prática, é possível entender que o impacto se dilui com o passar do tempo; ou seja, a variável instrumental perde seu poder de persuasão, invalidando esta metodologia de medição. Isso aconteceu porque a proporção de usuários que fazem o tratamento é inferior a 5%, de modo que o ITT é facilmente distorcido com os 95% restantes do grupo de teste.
Estudo de observação
Diante da evidência de que em longo prazo não é viável trabalhar com baixas proporções de usuários persuadidos (aqueles que recebem o tratamento) com experimentos randomizados, o Mercado Livre decidiu estimar o contrafactual dos usuários persuadidos, tomando o grupo controle como referência, de modo a responder à pergunta “o que eu teria feito se não tivesse aceitado o estímulo?”. Para isso, transformou o RCT (Randomized Controlled Trials em um estudo observacional, conforme abaixo:
CATE = E [Y (1) – Y (0) | X = x]
Com essa metodologia, é possível condicionar o grupo de teste escolhido aleatoriamente e manter apenas os que fizeram o tratamento versus todo o grupo de controle. Dessa forma, quebra-se a questão da aleatoriedade. Lembrando que, para fazer uma comparação justa sem viés, todas as co-variáveis anteriores devem ser iguais para ambos os grupos. Agora, vamos ver o que acontece quando olhamos para a frequência histórica de compra antes do estímulo.

Ou seja, assim como acontece com outras questões, os usuários que fazem o tratamento são melhores compradores do que a média. Isso porque os usuários mais experientes são os que costumam interagir com a plataforma com mais frequência. Mas isso também significa que a comparação não é justa, e deve ser ajustada. Nesse caminho, é preciso:
-
Identificar o gráfico causal, entendendo bloqueios e passagens no relacionamento;
-
Estimar métricas incrementais e escolher o estimador de melhor ajuste. Isso ajuda a resolver o problema da falta de contrafactuais e do viés de confusão;
-
Validar a robustez do estimador. Isso é realizado através de uma série de testes, como tratamento com placebo, adicionar uma causa comum aleatória e estipular um resultado fictício.
Conclusões
Depois de tudo o que analisamos até aqui, a partir do case Mercado Livre, foi possível mostrar a complexidade de medir o efeito das ações de uma empresa no longo prazo. E também entender que, sem as técnicas utilizadas, poderiam ter sido escolhidas técnicas tendenciosas, implicando em um relatório de lucro irreal para a empresa. Além disso, analistas com conhecimento de domínio teriam escolhido uma medida com variáveis instrumentais, o que levaria a resultados mais baixos e não muito repetíveis.
Como vimos, medir o impacto que os modelos atuais geram nos negócios de uma empresa pode ser muito complexo; por isso, do ponto de vista técnico, o case do Mercado Livre conseguiu demonstrar casos em que é necessário recorrer à inferência causal, tendo em vista a importância de avaliar diferentes estimadores e validar a robustez de cada um deles.
Quando o assunto é retenção de clientes, nada é simples. Mas a partir do auxílio da Ciência de Dados, é possível conseguir informações preciosas e importantes para o seu negócio, assim como realizar as melhores análises para conseguir o resultado ideal. Que, nesse caso, é estar em sintonia com seus consumidores, e conseguir prever de forma inteligente seu comportamento, entregando o necessário para mantê-lo fiel à sua marca – e, claro, melhorando seu negócio cada vez mais.


