

Os acordos de nível de serviço, tão difundidos em TI, podem ser aplicados de forma semelhante na jornada de dados das organizações
O Service Level Agreement (SLA) – ou Acordo de Nível de Serviço – estabelece as métricas pelas quais um serviço prestado por um cliente para um fornecedor é medido. Ele serve para definir o escopo de trabalho e estabelece as normas, acordos, metas e demais questões relacionadas a este serviço. Normalmente, os SLAs são entre empresas e fornecedores externos, mas também podem ser entre departamentos internos.
Por exemplo, o SLA voltado para o cliente do Slack promete 99,99% de tempo de atividade a cada trimestre fiscal para seus clientes, e não mais do que 10 horas de tempo de inatividade programado. Se falharem, os clientes afetados receberão créditos de serviço em suas contas para uso futuro.
Amplamente utilizado em TI, um SLA aplicado aos dados tem uma lógica semelhante, porém, em contextos diferentes.
Assim como o desenvolvimento de software em geral, as equipes de dados encaram um desafio significativo, que é a confiabilidade. As empresas estão gerando cada muitos dados e também utilizando de terceiros. Equipes de todos os setores utilizam esses dados cada vez mais e, ao mesmo tempo. Nesse sentido, as fontes, os pipelines e fluxos de trabalho são super complexos.
Por isso tornou-se uma necessidade crítica para as equipes de dados e seus consumidores definir, medir e rastrear a confiabilidade em todo o seu ciclo de vida. Podemos dizer que os SLAs de dados é de alguma maneira uma necessidade metalínguística: ter mais dados para controlar a própria eficiência dos dados.
Esses SLAs também formalizam e agilizam a comunicação, garantindo que as equipes e seus stakeholders falem a mesma língua e façam referência às mesmas métricas. E como o processo de definição de SLAs ajuda a equipe de dados a entender melhor as prioridades do negócio, eles serão capazes de priorizar rapidamente e acelerar os tempos de resposta quando ocorrerem incidentes
O case do Airbnb
Ter um SLA bem definido para trabalhar com Big Data ajuda, principalmente, os líderes de negócios que precisam das respostas dos dados com mais frequência. Ter o pipeline de dados atualizado, funcionando e com um bom nível de confiabilidade evita que o tomador de decisão fique “cego”, ou seja, sem dados atualizados que reflitam a realidade.
No entanto, isso pode ser difícil de fazer porque a jornada da coleta até o output final normalmente requer muitas etapas. É o que acontece no Airbnb – e em qualquer lugar com pipelines de processamento de dados em grande escala. Os conjuntos de dados “brutos” são limpos, mesclados e ganham estrutura , que potencializam os recursos do produto e permitem a análise para informar as decisões de negócios.
Em artigo no blog da empresa é relatado o desenvolvimento do SLA Tracker, uma ferramenta de análise visual para facilitar a cultura de atualização dos dados. Com este produto, a empresa sistematizou soluções para desafios de atualização de dados, como:
-
Quando um conjunto de dados deve ser considerado atrasado?
-
Com que frequência os conjuntos de dados atrasam?
-
Por que um conjunto de dados está atrasado?
Para garantir a pontualidade dos outputs dos dados, os proprietários de cada etapa intermediária se comprometam com Acordos de Nível de Serviço (SLAs) para a disponibilidade de seus dados em um determinado período. Por exemplo, o proprietário do conjunto de dados promete que a métrica de “reservas” terá os dados mais recentes às 17h e, se não estiver disponível a essa hora, será considerada “atrasada”.
Na visualização do SLA Tracker, os produtores de dados podem rastrear tendências históricas e em tempo real em vários conjuntos de dados que eles possuem ou com os quais se preocupam.
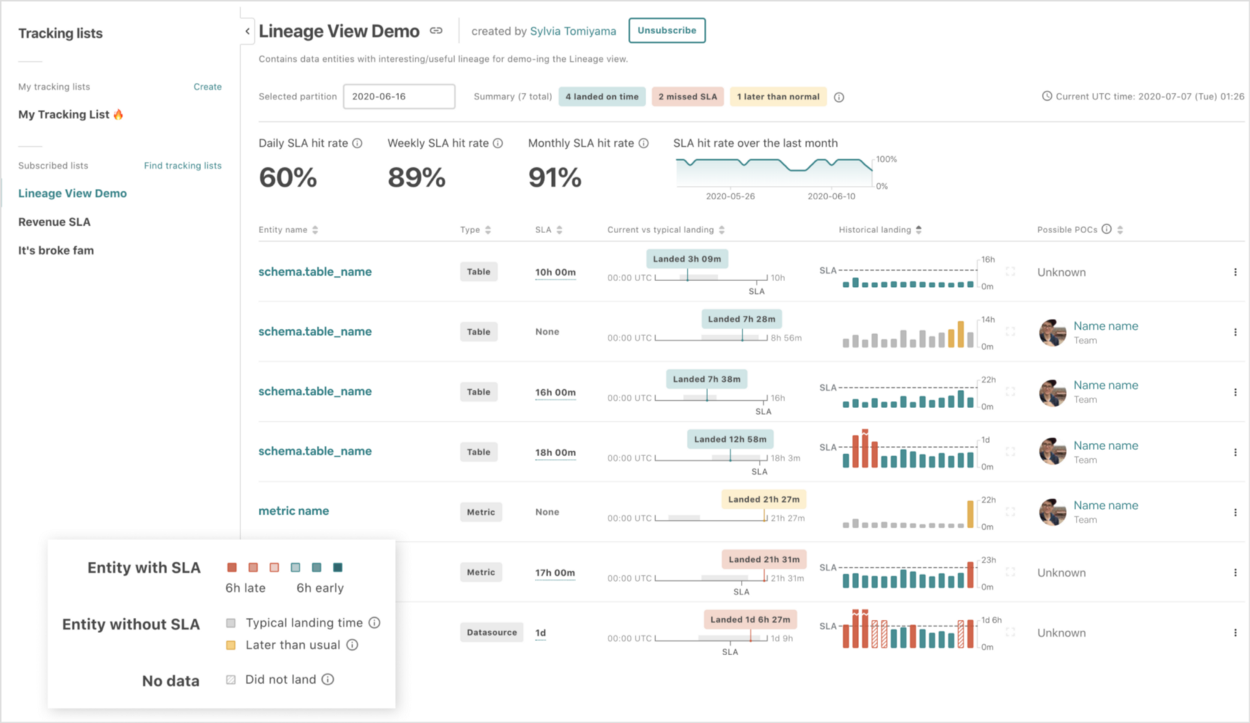
O SLA Tracker fornece uma visão geral de alto nível do desempenho de SLA em listas de conjuntos de dados. Cada linha inclui um indicador de status da partição de dados mais recente e gráficos de barras que exibem horários de aterrissagem históricos (as barras vermelhas mostram os dias em que os conjuntos de dados perderam os SLAs).
A visualização de Relatório faz uso de listas tradicionais de entidades de dados, com pequenos visuais incorporados que resumem os dados de tempo de aterrissagem típicos e históricos. Os produtores de dados podem organizar seus conjuntos em listas e colaborar com outras pessoas (por exemplo, sua equipe).
Com esse resumo, entender os tempos de aterrissagem e o desempenho do SLA tornou-se tão simples quanto selecionar uma lista de conjuntos de dados.
Os conjuntos de dados não são independentes uns dos outros. São derivados passo a passo em uma sequência específica, onde uma ou mais transformações devem acontecer antes da outra, como mostra a imagem abaixo:

Um exemplo de linhagem de dados para a criação do conjunto de dados “A”. “A” depende de “B”, que depende de “C” e “D” e assim por diante.
Assim, a disponibilidade de um conjunto de dados está ligada a uma “linhagem” hierárquica. Para definir um SLA realista para um conjunto de dados, é preciso levar em consideração toda a sua árvore de dependências – às vezes compreendendo centenas de entidades – e seus próprios SLAs.
Para aumentar a complexidade, quando as coisas dão errado, tentar combinar as dependências hierárquicas com a sequência temporal torna os erros de SLA difíceis de raciocinar sem auxílio visual. As ferramentas existentes no Airbnb permitiam que os engenheiros identificassem problemas em seus próprios pipelines de dados, mas era muito mais difícil fazer isso em pipelines de equipes diferentes. Com o SLA Tracker, isso ficou centralizado em um só lugar e de forma bem visual.
Para conjuntos de dados com árvores de dependência muito grandes, era difícil encontrar as etapas de “gargalo” que atrasavam todo o pipeline de dados. O SLA Tracker conseguiu reduzir drasticamente o ruído e destacar esses conjuntos de dados problemáticos, desenvolvendo o conceito de um caminho de “gargalo” – a sequência dos ancestrais de dados mais recentes que impediu o início de uma transformação de dados filho, atrasando assim todo o pipeline.

A visualização da linha de tempo dá uma noção clara da sequência e da duração das transformações de dados, enquanto preserva dependências hierárquicas importantes que fornecem contexto de sequência. Os tempos de pouso históricos são exibidos para cada linha do conjunto de dados, à esquerda da execução atual.
Depois do gargalo identificado, a próxima questão importante passou a ser se o atraso nessa etapa era devido a longos tempos de execução ou atrasos nas dependências upstream. Isso ajuda os produtores de dados a entender se precisam otimizar seu próprio pipeline ou, em vez disso, negociar com proprietários de conjuntos de dados upstream para SLAs anteriores. Para permitir isso, foi construída uma visão dos tempos de execução históricos detalhados de um único conjunto de dados, mostrando quando eles foram executados e a duração:

Os tempos de execução históricos e as distribuições de duração distinguem rapidamente se as perdas de SLA (vermelho) são devidas ao início tardio (parte superior) e durações de tempo de execução longas (parte inferior).
Ao combinar essas visualizações complementares no SLA Tracker, foi possível fornecer uma perspectiva completa do nível de atualização dos dados.

O SLA Tracker é composto de várias visualizações. A visualização Relatório fornece uma visão geral do status do conjunto de dados, a visualização Linhagem permite a análise da causa raiz dos tempos de desembarque dos dados e a visualização Histórico captura tendências históricas em detalhes.
O Projeto como um todo levou 12 meses para ser concluído, exigindo trabalho de front-end, back-end, engenharia de dados, além de design de UI/UX para garantir uma boa visualização de dados, parte importante para a ferramenta ser difundida na empresa, gerando uma boa experiência aos usuários internos.
Embora a complexidade possa até assustar, existem alguns passos para começar a melhorar os SLAs de confiabilidade dados nas empresas. Quem explica é Barr Moses em . Basicamente, são três etapas: definição, medição e rastreamento.
Etapa 1: Definindo a confiabilidade dos dados com SLAs
A primeira etapa é chegar a uma concordância e definir claramente o que dados confiáveis significam para a organização. É possível começar conduzindo um inventário de dados, como eles estão sendo usados e por quem.
Ao criar acordos de confiabilidade com equipes internas, é vital entender como os consumidores realmente interagem com os dados, quais são mais importantes e quais problemas em potencial requerem atenção imediata e rigorosa.
Depois de entender com quais dados as pessoas trabalham, como eles são usados e quem os usa, será possível definir SLAs claros e acionáveis.
Etapa 2: Medir a confiabilidade dos dados com SLIs
O segundo passo é começar a se concentrar nas principais métricas que se tornarão os indicadores de confiabilidade de nível de serviço (SLIs).
Como regra geral, os SLIs devem representar o estado de dados mutuamente acordado na etapa 1, fornecer limites de como eles são usados e descrever especificamente como é o tempo de inatividade. Isso pode incluir cenários como dados ausentes, duplicados ou desatualizados.
Algumas métricas usadas aqui:
-
O número de incidentes de dados para um determinado ativo de dados (N): Embora isso possa estar além do controle, visto que provavelmente depende de fontes de dados externas, ainda é um fator importante para o tempo de inatividade dos dados.
-
Tempo para detecção (TTD): quando surge um problema, essa métrica quantifica a rapidez com que a equipe é alertada. Se não houver métodos adequados de detecção e alerta, isso pode ser medido em semanas ou até meses. “Erros silenciosos” cometidos por dados incorretos podem resultar em decisões caras, com repercussões tanto para empresa quanto para os clientes.
-
Tempo para resolução (TTR): quando a equipe é alertada sobre um problema, mede a rapidez com que é capaz de resolvê-lo.
Etapa 3: rastrear a confiabilidade dos dados com SLOs
Os SLOs são medidas quantitativas de qualidade de serviço e objetivos de nível de serviço. Esses SLOs devem ser realistas e baseados nas circunstâncias do mundo real. Por exemplo, se decidir incluir TTD como uma métrica, mas não usar nenhuma ferramenta de monitoramento automatizada, o SLO deve ser um intervalo inferior ao de uma organização madura com ferramentas de observabilidade de dados abrangentes.
Concordar com esses intervalos permite criar uma estrutura uniforme que classifica os incidentes por nível de gravidade e simplifica a comunicação e a resposta rápida quando surgem problemas.
Essas três etapas são um bom começo. Elas fornecem uma estrutura útil para medir o tempo de inatividade de dados e podem ajudar a construir uma cultura baseada em dados, de colaboração e confiança em toda a sua organização,


