
Um exemplo hipotético a partir de modelos de previsão de churn
Na ciência de dados, os modelos são construídos para que possam fazer previsões sobre determinados cenários, embasando tomadas de decisões e ações em cima deles.
Essa relação entre previsão e ação pode ser bem direta. Em um exemplo simples: ao sair de casa para ir ao trabalho, você pode decidir se leva ou não guarda-chuva. Você olha a previsão do tempo e prevê a chance de chuva ao longo do dia. Se for o alta o suficiente, decide levar o guarda-chuva. Se não, opta por deixar o guarda-chuva em casa.
Essa relação entre previsão e ação também pode ser mais complexa, envolvendo diversas variáveis. Tomamos como exemplo uma situação hipotética, com cientistas de dados de uma empresa de assinatura como a Netflix. Eles desejam evitar que os clientes cancelem sua assinatura mensal, oferecendo incentivos para permanecerem como clientes.
Aqui, é possível aplicar um approach padrão – mas muito eficiente – envolvendo Data Science e Machine Learning: primeiro, se coletam os dados históricos sobre clientes que cancelaram e clientes que não cancelaram a assinatura. Inserem-se seus atributos, suas interações com a plataforma, seu comportamento, formando um “vetor de recursos” para cada cliente e então chegamos a um conjunto de dados:

Com esse conjunto de dados, se constrói um modelo como uma regressão logística que, dado o vetor de recursos, prevê a probabilidade de churn:
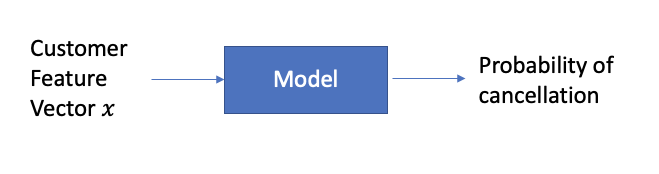
Este modelo pode ter centenas ou milhares de variáveis para cada cliente e pode ser construído com métodos avançados, como Deep Learning ou XGBoost. Mas o que se deve fazer com esse modelo?
Uma ação até óbvia poderia ser entrar em contato com os clientes com alta probabilidade de previsão de churn e oferecer uma recompensa ou desconto pela renovação da assinatura. Isso pode funcionar para alguns clientes, mas certamente não para todos.
Alguns clientes irão ignorar a recompensa e cancelar o serviço de qualquer forma. Outros podem nem mesmo pensar em sair, mas ficarão contentes com a recompensa e a ação será desperdiçada. E ainda para outros que podem nem estar pensando em sair, talvez a recompensa os lembre que não estão usando o serviço e podem acabar cancelando tudo.
A questão é que clientes podem reagir de formas diferentes a diferentes ações. Um cliente pode renovar o contrato se ganhar um cupom de 20% de desconto, mas se a oferta for “aumente a transmissão do seu pacote de streaming para mais dois dispositivos sem custos adicionais”, pode não ter o mesmo efeito. Já para outro cliente, pode ser exatamente o contrário.
Imagine agora se fosse possível prever a probabilidade de rotatividade quando um cliente é visado com cada ação possível, incluindo a ação de “não fazer nada”.

Este já é um bom ponto de partida. Olhando mais para o resultado financeiro, como o lucro esperado de cada cliente nos próximos 12 meses, dá para conhecer o impacto de custo e receita de cada ação e transformar o modelo acima para este:

Com este modelo em mãos é possível prever o resultado esperado de acordo com cada ação para qualquer cliente.
Padronização dos outputs
O ponto aqui é a questão da padronização dos outputs desses modelos para melhorar a tomada de decisões. É o que aborda em uma série de artigos no Medium o cientista de dados e PhD Rama Ramakrishnan.
Por exemplo: uma função que atribui uma ação a cada vetor de recursos é chamada de política.
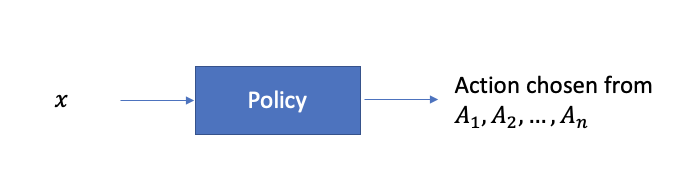
Uma função que atribui a melhor ação a cada vetor de recursos é uma política ótima.

Ou seja, no nosso exemplo em questão, qual é a política de segmentação ideal que deve ser aplicada a cada cliente para maximizar o lucro esperado com a redução de churn? Ou seja, qual a padronização ideal para trabalhar sempre esses outputs para que possam apoiar a tomada de decisão?
Vamos imaginar que temos dados de um experimento aleatório: uma amostra de clientes foi escolhida aleatoriamente e, em seguida, atribuída aleatoriamente a uma das três ações – 20% de desconto, transmitir mais dois dispositivos e não fazer nada – e sua resposta de renovação/cancelamento foi registrada.
Assim, podemos construir três modelos de classificação padrão:

Com esses três modelos em mãos, é fácil encontrar a política ideal: executar o x de qualquer cliente em cada modelo, obter as três probabilidades de cancelamento previstas, traduzir em lucro esperado (ou qualquer resultado financeiro que seja de interesse) e escolher a ação com o maior lucro esperado.
A avaliação e otimização de políticas usando técnicas como essa é algo que faz a ciência de dados gerar muito valor no dia a dia, mas na prática ela é pouco utilizada.
Conjunto de dados
Para aprender as políticas ideais, precisamos reunir os dados certos. E o conjunto de dados ideal para o aprendizado de políticas vem de um experimento aleatório, composto em três etapas:
-
Etapa 1: selecionar uma amostra aleatória da base de clientes;
-
Etapa 2: decidir como atribuir ações aleatoriamente a cada cliente da amostra;
-
Etapa 3: executar o experimento e coletar dados sobre os resultados.
A Etapa 1 é feita diretamente. Para a etapa 2, vamos lembrar que temos três ações consideradas: 20% de desconto para o próximo ano, transmitir mais dois dispositivos e não fazer nada. Vamos distribuir cada uma aleatoriamente a cada cliente:

Podemos escolher qualquer probabilidade para cada combinação de ação do cliente, desde que duas condições sejam satisfeitas:
-
Para qualquer cliente, as probabilidades de todas as ações devem somar 1,0 (ou seja, a soma das probabilidades em cada linha deve ser 1,0). Isso apenas garante que exatamente uma ação seja atribuída a cada cliente.
-
Cada probabilidade deve ser diferente de zero. Isso garante que cada ação tenha a chance de ser atribuída a um cliente.
Se trabalharmos com probabilidades que satisfaçam essas duas condições, os conjuntos de dados resultantes podem ser usados com segurança para avaliação e otimização de padronizações.
Aqui está um exemplo de probabilidades que satisfazem as duas condições:

Vale observar que as probabilidades são diferentes para clientes diferentes. Isso é totalmente correto, pois não viola as duas condições acima. Na verdade, essa capacidade de escolher diferentes probabilidades para diferentes clientes nos dá uma enorme flexibilidade.
Também importante destacar que tabela acima é uma espécie de padronização: dado x, em vez de escolher uma ação específica, escolhemos uma ação aleatoriamente de acordo com as probabilidades definidas para esse x. Uma política que satisfaça as duas condições acima é chamada de política de comportamento na literatura de Aprendizagem por Reforço, mas também pode ser chamada de política de coleta de dados.
Essa liberdade de escolher diferentes probabilidades para diferentes clientes pode ser muito útil na prática. Uma situação comum é quando não queremos desperdiçar uma ação “cara” (por exemplo, um desconto de 50%) com clientes que provavelmente não precisará dela.
Concretamente, digamos que queremos aplicar a ação de “20% de desconto para o próximo ano” apenas para clientes com alta probabilidade de cancelamento, e não para outros, uma vez que suspeitamos que clientes com baixo risco podem apenas embolsar a recompensa.
Primeiro, usamos dados históricos para construir um modelo para prever a probabilidade de cancelamento para cada cliente.

Podemos usar qualquer abordagem de classificação para construir este modelo, desde que forneça uma previsão de probabilidade em vez de apenas uma previsão de classe 0-1. Executamos este modelo na amostra de clientes:

Agora, considerando um cliente na amostra cuja probabilidade prevista de cancelamento é p. Para este cliente, definimos a probabilidade de ser atribuído a ação “20% de desconto no próximo ano” para p. A probabilidade restante (ou seja, 1- p) e dividida igualmente entre as outras ações: “transmitir mais dois dispositivos” obtém uma probabilidade de (1-p) / 2 e “não fazer nada” obtém (1-p) / 2 .

É fácil confirmar que esta é uma política de coleta de dados válida: todos os três números são diferentes de zero e, claro, eles somam 1,0.
Aplicando essa lógica, obtemos esta política de coleta de dados:

A probabilidade de cancelamento para o primeiro cliente é de 70%, portanto, “20% de desconto” obtém uma probabilidade de 70%, “transmitir mais dois dispositivos” obtém 15% e “não fazer nada” obtém 15%.
Podemos ver que os clientes com uma probabilidade de cancelamento prevista baixa (por exemplo, o último cliente no exemplo) têm uma chance baixa de obter o dispendioso desconto de “20% de desconto”, que é o que queríamos.
Uma vez que uma política de coleta de dados válida tenha sido especificada, chegamos à etapa 3: executando o experimento e medindo os resultados.
Esta etapa é simples: para cada cliente na amostra, selecionar aleatoriamente uma ação de acordo com as suas probabilidades, aplicar a ação selecionada a esse cliente, e medir o resultado.
Para um cliente com probabilidade de 70% -15% -15% para as três ações, por exemplo, é possível gerar um número aleatório uniforme no intervalo de 0-1 e se o valor estiver entre 0,0-0,7, escolha “20% de desconto para o próximo ano”; se estiver entre 0,70–0,85, escolha“ transmitir mais dois dispositivos ” e se estiver entre 0,85–1,0, escolha “não fazer nada”.
Quando o experimento for concluído, os dados finais ficarão assim:

Acrescentamos mais duas colunas: a ação real atribuída a cada cliente e o valor do resultado. Para simplificar, há um resultado binário, mas podemos usar qualquer coisa (por exemplo, o lucro do próximo ano).
Este é apenas um exemplo hipotético de como podemos definir com flexibilidade uma política de coleta de dados para acomodar as considerações de negócios. A partir disso, diversas outras políticas de coleta de dados podem ser definidas de acordo com a realidade de cada empresa.


