

Saiba mais sobre como a Ciência de Dados potencializa a a análise de sentimento e os seus benefícios e aplicações em diversos segmentos
A análise de sentimento é uma técnica de processamento de linguagem natural usada para determinar a valência e a caracterização das emoções transmitidas via conteúdos em texto ou áudio. Ela é realizada com mais frequência em dados de texto para ajudar as empresas a monitorar a opinião das pessoas sobre suas marcas e produtos via redes sociais.
Ela se torna importante porque ajuda as empresas a compreender rapidamente as opiniões gerais de seus clientes ou o impacto de um posicionamento, uma campanha ou uma notícia entre as pessoas em geral. Classificar automaticamente o sentimento por trás dessas conversas online gera um ingrediente a mais para tomar decisões estratégicas.
Um exemplo básico é utilizar a análise de sentimento para avaliar automaticamente mais de 4.000 comentários existentes sobre um produto em redes sociais, sites, e-mails, ajudando a entender se os clientes estão satisfeitos ou o que pode ser melhorado, em termos de funcionalidades, preços e atendimento.
Um ponto-chave é que cerca de 90% dos dados mundiais são desestruturados. Grandes volumes de dados de negócios não estruturados são criados todos os dias: e-mails, tíquetes de suporte, chats, conversas em mídias sociais, pesquisas, artigos, documentos, e por aí vai. Então, é preciso estruturá-los primeiro, para alimentar um modelo de Aprendizado de Máquina para só depois analisar o sentimento de maneira oportuna e eficiente.
Existem três tipos de algoritmos que podem ser implementados em modelos de análise de sentimento, dependendo de quantos dados precisam ser analisados e qual a precisão necessária. São eles: baseado em regras, automáticos ou híbridos.
Baseado em regras
Esses sistemas executam análises de sentimento automaticamente com base em um conjunto de regras criadas manualmente, ajudando a identificar subjetividade, polaridade ou o assunto de uma opinião. Elas podem incluir várias técnicas de NLP desenvolvidas em linguagem de computação, como derivação, tokenização, marcação e análise de classes gramaticais, lexicons (listas de palavras e expressões).
Um exemplo básico de como funciona um sistema baseado em regras:
-
Defina duas listas de palavras polarizadas (por exemplo, palavras negativas como ruim, pior, feio, e palavras positivas como bom, o melhor, bonito, etc);
-
Conte o número de palavras positivas e negativas que aparecem em um determinado texto;
-
Se o número de ocorrências de palavras positivas for maior do que o número de ocorrências de palavras negativas, o sistema retornará um sentimento positivo e vice-versa. Se os números forem pares, o sistema retornará um sentimento neutro.
Os sistemas baseados em regras são muito ingênuos, pois não levam em consideração como as palavras são combinadas em uma sequência. Obviamente, técnicas de processamento mais avançadas podem ser usadas e novas regras adicionadas para oferecer suporte a novas expressões e vocabulário. No entanto, adicionar novas regras pode afetar os resultados anteriores e todo o sistema pode ficar muito complexo. Como os sistemas baseados em regras geralmente exigem ajustes e manutenção, eles também precisam de investimentos regulares.
Automático
Já os sistemas automáticos contam com técnicas de aprendizado de máquina para aprender com os dados. Uma tarefa de análise de sentimento geralmente é modelada como um problema de classificação, em que um classificador é alimentado com um texto e retorna uma categoria – por exemplo, positivo, negativo ou neutro.
Veja como um classificador de aprendizado de máquina pode ser implementado:

Os processos de treinamento e previsão
No processo de treinamento, o modelo aprende a associar uma determinada entrada (ou seja, um texto) à saída correspondente (tag) com base nas amostras de teste usadas para o treinamento. O extrator de variáveis transfere a entrada de texto em um vetor de variável. Pares de vetores de variáveis e tags (positivo, negativo ou neutro) são alimentados no algoritmo de aprendizado de máquina para gerar um modelo.
No processo de previsão (b), o extrator de características é usado para transformar entradas de texto não vistas em vetores de características. Esses vetores são alimentados no modelo, que gera tags previstas (positivas, negativas ou neutras).
Conversão de texto em variáveis
A primeira etapa em um classificador de texto de aprendizado de máquina é transformar a extração ou vetorização do texto, e a abordagem clássica tem sido um saco de palavras ou um saco de ngrams com sua frequência.
Mais recentemente, novas técnicas de extração foram aplicadas com base em embeddings de palavras (também conhecidos como vetores de palavras). Esse tipo de representação possibilita que palavras com significados semelhantes tenham uma representação semelhante, o que pode melhorar o desempenho dos classificadores.
Algoritmos de Classificação
A etapa de classificação geralmente envolve um modelo estatístico como Naive Bayes, Regressão Logística, Máquinas de Vetores de Suporte ou Redes Neurais:
-
Naive Bayes: uma família de algoritmos probabilísticos que usa o Teorema de Bayes para prever a categoria de um texto;
-
Regressão Linear: um algoritmo muito conhecido em estatística usado para prever algum valor (Y) dado um conjunto de características (X).
-
Máquinas de Vetores de Suporte: um modelo não probabilístico que usa uma representação de exemplos de texto como pontos em um espaço multidimensional. Exemplos de diferentes categorias (sentimentos) são mapeados para regiões distintas dentro desse espaço. Em seguida, novos textos são atribuídos a uma categoria com base nas semelhanças com os textos existentes e as regiões para as quais eles são mapeados.
-
Aprendizado profundo: um conjunto diversificado de algoritmos que tentam imitar o cérebro humano, empregando redes neurais artificiais para processar dados.
Leia mais: Um tour pelos 10 principais algoritmos de Machine Learning
Sistemas híbridos
Os sistemas híbridos, basicamente combinam abordagens baseadas em regras e automáticas mostradas anteriormente, buscando alcançar resultados mais precisos.
Afinal, a análise de sentimento é uma tarefa difícil por conta dos diversos nuances dos sentimentos humanos que podem ser expressas por meio dos textos. Por exemplo, questões envoltas em subjetividade e tom. Aqui, existem dois tipos de texto: subjetivo e objetivo. Textos objetivos não contêm sentimentos explícitos, enquanto textos subjetivos sim. Por exemplo, para analisar o sentimento dos seguintes comentários:
O produto é bom.
O produto é verde.
A maioria das pessoas diria que o sentimento é positivo para o primeiro e neutro para o segundo. Todos os predicados (adjetivos, verbos e alguns substantivos) não devem ser tratados da mesma forma no que diz respeito a como eles criam sentimento. Nos exemplos acima, bom é mais subjetivo do que verde.
Esse é um ponto e ainda há outros, como entender os contextos. Por exemplo, respostas como: “Tudo isso” e “Absolutamente nada!” podem ter pesos diferentes se as perguntas forem diferentes, como “o que você gostou no evento?” ou “o que você NÃO gostou no evento?”.
Também há figuras de linguagem como ironia e sarcasmo, quando queremos expressar sentimentos negativos usando palavras positivas e vice-versa, além de comparações e até mesmo algo próprio da Internet que são os emojis.
Uma boa dose de pré-processamento ou pós-processamento é necessária para levar em conta pelo menos parte dos contextos em que os textos foram produzidos – e isso é bastante complexo de ser executado.
Ainda assim, é importante dizer, a análise de sentimento vale à pena, mesmo que as previsões estejam erradas de vez em quando. Afinal, é melhor ter 60, 70 ou 80% de previsões corretas do que não ter nada e dar um tiro no escuro. Para casos de uso típicos, como tíquetes de suporte, monitoramento de marca e atendimento ao cliente, a economia de tempo e recursos diante de tarefas manuais trabalhosas e chatas já vale a automatização.
Um caso de uso na Uber
Uma das empresas que utiliza análise de sentimento em grande escala é a Uber. Ela recebe muitos comentários, sugestões e reclamações dos usuários diariamente em todo o mundo. A enorme quantidade de dados recebidos torna a análise, categorização e geração de insights uma tarefa desafiadora.
Em artigo no Towards Data Science, o cientista de dados Shashank Gupta analisou conversas em mídias digitais sobre alguns temas de produtos: Cancelamento, Pagamento, Preço, Segurança e Serviço.
Aqui está uma distribuição de pontos de dados em todos os canais:
-
Facebook: 34.173 comentários
-
Twitter: 21.603 tweets
-
Notícias: 4.245 artigos
Analisar os sentimentos das conversas dos usuários pode dar uma ideia sobre as percepções gerais da marca. Mas, para ir mais a fundo, é importante classificar ainda mais os dados com a ajuda da Pesquisa Semântica Contextual, um algoritmo de pesquisa inteligente também chamado de CSS, que leva em consideração todas as mensagens e um conceito (como Preço) como entrada e filtra todas as mensagens que correspondem ao input fornecido. O gráfico abaixo demonstra como o CSS representa uma grande melhoria em relação aos métodos existentes usados pela indústria.
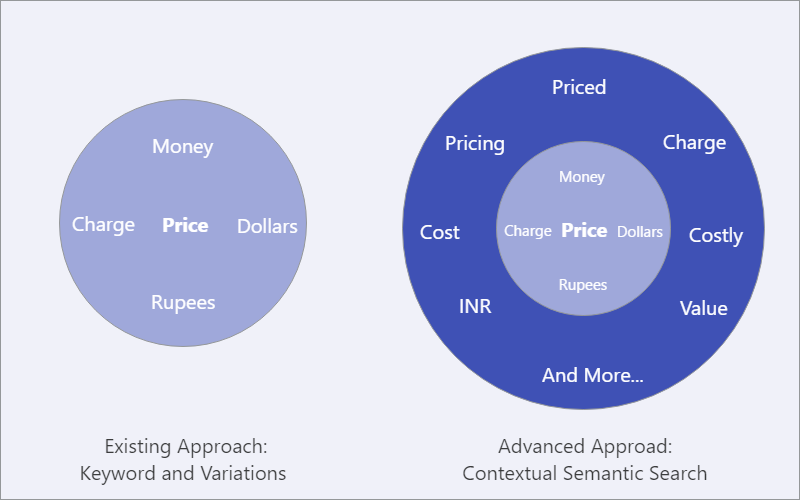
Abordagem existente versus pesquisa semântica contextual
No caso da Uber, aplicando CSS nas categorias apresentadas:

Os comentários relacionados a todas as categorias têm um sentimento negativo principalmente, exceto um. O número de comentários positivos relacionados ao preço superou os negativos. Para cavar mais fundo, analisou-se a intenção desses comentários:
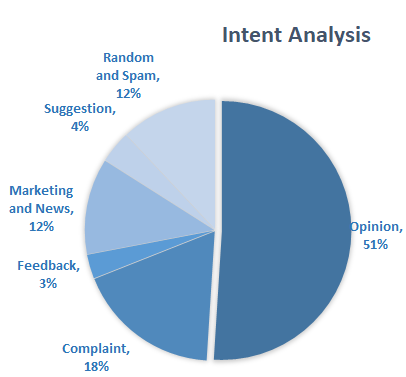
Assim, removeu-se todas as categorias de intenção irrelevantes e reproduzindo o resultado:

Há uma mudança perceptível no sentimento associado a cada categoria. Especialmente nos comentários relacionados a preços, onde o número de comentários positivos caiu de 46% para 29%. Isso fornece uma ideia de como os algoritmos podem gerar insights detalhados a partir da mídia digital.
Uma marca pode, portanto, analisar tais comentários e tomar decisões melhores baseados no que as pessoas estão dizendo sobre pontos positivos ou feedbacks negativos. O estudo de caso do Uber dá uma ideia do que é possível fazer para aproveitar o poder dos dados e obter informações mais profundas.


