

A escassez de dados é um problema pra boa parte da organizações que desejam integrar soluções de AI nas suas práticas e estratégias.
Ao contrário das empresas de Internet, como as “Big Nine” (Amazon, Google, Facebook, Tencent, Baidu, Alibaba, Microsoft, IBM e Apple) e outras, que possuem dados de bilhões de usuários para treinar poderosos modelos de IA, a coleta massiva de dados em empresas de médio e pequeno não é uma realidade.
Por exemplo, em uma pesquisa recente do MAPI junto ao setor de manufatura, 58% dos respondentes relataram que a barreira mais significativa à implantação de soluções de IA refere-se à falta de recursos de dados.

Mas, se por um lado os grandes volumes de dados permitiram que as gigantes da internet avancem fortemente na aplicação de inteligência artificial, recentes experimentações em AI estão tornando possível também o funcionamento de estratégias e práticas de treinamento de modelos em realidades de “small data”.
Alguns exemplos de técnicas
Claro que a robustez dos algoritmos e projetos não é a mesma, mas algumas técnicas têm sim tido sucesso em tentar contornar o problema do baixo volume de dados, mesmo que de forma experimental e exploratória.
Aprendizado por transferência
O “transfer learning” é uma técnica que permite que a inteligência artificial em desenvolvimento, sem grandes volumes de dados, aprenda (seja treinada) com dados de uma tarefa ou atividade relacionada (para a qual haja dados disponíveis o suficiente).
Em seguida, ela usa então o conhecimento construído (o aprendizado/treinamento alcançado) para ajudar a resolver o problema que, a princípio, tem poucos dados para ser explorado.
Por exemplo, uma IA pode aprender a identificar e encontrar informações sobre superfícies amassadas em peças automotoras a partir de um grande banco de imagens advindas de diversos datasets secundários (adquiridos de outras empresas ou encontrados em plataformas gratuitas de disponibilização de bancos de dados e de imagens). Na sequência, após analisá-las, classificá-las, segmentá-las, clusteriza-las, etc., pode-se então transferir esse conhecimento (com base nos parâmetros identificados) para detectar itens ou partes amassadas em produtos específicos sobre os quais não se tem grande quantidade de dados a respeito.

Fonte: Research Gate
Conhecimento codificado manualmente
No “hand-coded knowledge” a equipe de IA (ou a equipe responsável pela iniciativa de uso de prática de IA) realiza entrevistas com especialistas nas áreas de interesse do experimento — sejam estes especialistas internos de uma organização ou profissionais do mercado em geral — e executa um processo de codificação do máximo do conhecimento institucional possível em um sistema (para que os dados levantados e codificados/classificados fiquem registrados num banco de dados). Essa é uma forma de dar início à construção de um banco de dados.
Por exemplo, uma rede de lanchonetes pode criar uma planilha e pedir que os gerentes de cada PDV respondam uma série de perguntas e critérios sobre determinado processo ou sobre a performance de vendas e registrem tudo num formulário ou planilha. A partir do conhecimento dos gerentes, portanto, poderá ser iniciado uma base para construção de algoritmos futuros de aprendizado (que serão treinados com base nas informações oferecidas por especialistas).
O aprendizado de máquina robusto é focado em construir sistemas que dependem de dados e não de conhecimento institucional humano. Mas, quando não se tem volume de dados disponível, pode-se projetar perfeitamente um sistema inicial que aproveite o conhecimento humano (organizacional ou de mercado) a respeito de determinado tema, processo, produto, performance, etc., para se dar início a projetos de AI.

Fonte: Unsplash
Detecção de anomalias
Na “anomaly detection” a inteligência artificial não é treinada com base em exemplos de imagens de produtos com “defeitos” (discrepâncias, diferenças de design, etc.), apenas com imagens perfeitas de determinados produtos (ou com dados e imagens de pessoas, mapas, situações, gráficos de produção, curvas de performance, condições de temperatura e até condições de pressão — pro caso de previsão de tornados, por exemplo).
Dessa forma, tendo uma grande base de treinamento criada a partir da definição de como as coisas podem se comportar (seja uma curva de performance de produção ou imagens de barragens de mineração) o algoritmo aprende a sinalizar como eventuais problemas (ou desvios em potencial) qualquer coisa que desvie significativamente da realidade que foi classificada como “OK” (perfeita, aceitável, sem riscos, etc.).
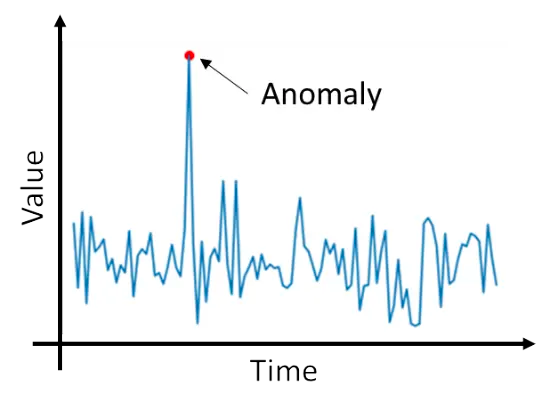
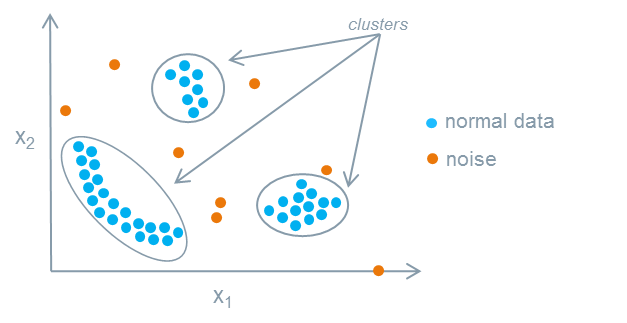
Fonte: Siemens Developers
Embora os projetos de AI atinjam suas performances máximas em cenários nos quais a quantidade de dados deixa de ser um problema (haja visto a arrancada da China nesse cenário, afinal, além de investimento, eles têm uma população enorme e gerando muitos dados), usar uma ou mais das abordagens comentadas (ou quaisquer outras que estejam sendo desenvolvidas com foco em suprir a lacuna de grandes volumes de dados) pode ser uma alternativa importante para se criar modelos eficazes de inteligência artificial.
Superar essa barreira é um passo fundamental para que as empresas em geral comecem a experimentar as possibilidades trazidas pela AI.


