Inspirada no cérebro humano, as redes neurais existem há mais de 50 anos, mas somente em 2012 ‘explodiram’ na área de Inteligência Artificial, abrindo portas para inovações em grandes companhias, graças a Big Data e ao poder da computação.
As redes neurais são um meio de fazer Aprendizado de Máquina, onde o computador aprende a realizar uma tarefa analisando exemplos de treinamento, que normalmente são indicados manualmente com antecedência.
Como qualquer outro modelo, a rede neural busca fazer uma boa previsão a partir de dados. Mas aqui isso acontece com questões mais sofisticadas e complexas como softwares que reconhecem automaticamente o rosto das pessoas ou os smartphones que transcrevem palavras faladas em texto ou ainda os carros autônomos que reconhecem objetos na estrada e desviam o trajeto.
Isso porque as redes neurais são um formato de estrutura de dados inspirada nas redes de neurônios do cérebro humano. Elas baseiam uma área da Inteligência Artificial chamada de Deep Learning. Essas redes neurais são organizadas em uma lógica de camadas e nós dentro dos códigos de programação, sugerindo uma estrutura vagamente similar ao que ocorre com os neurônios.
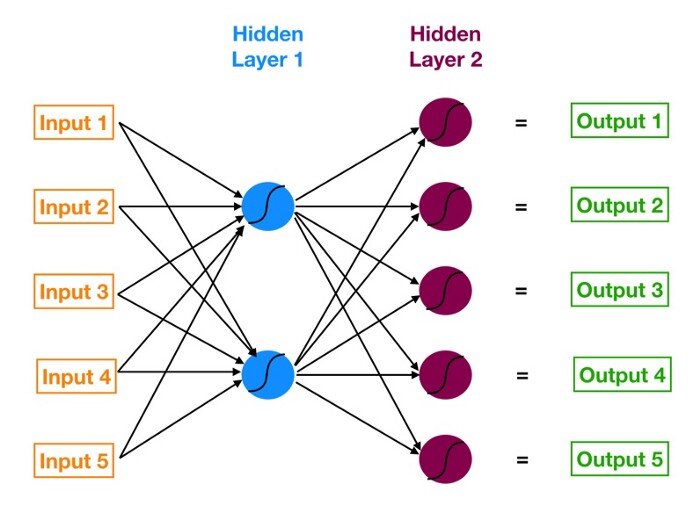
Acima temos uma Imagem de representação de uma rede neural de Deep Learning. É um diagrama de uma rede neural simples com 5 entradas, 5 saídas e duas camadas ocultas de neurônios. A partir da esquerda, temos a camada de entrada do modelo, na cor laranja, que são os dados que ele vai receber, normalmente bastante desestruturados. A seguir, a primeira camada oculta de neurônios, em azul. Na sequência, a segunda camada oculta de neurônios, em magenta. E por fim, em verde, a camada de saída do modelo, também conhecida como previsão. As setas que conectam os pontos mostram como todos os neurônios estão interligados e como os dados viajam da camada de entrada até a camada de saída.
A maioria dessas redes neurais é organizada em camadas de nós “feed-forward”, o que significa que os dados se movem por elas em apenas uma direção. Um nó individual pode ser conectado a vários nós na camada abaixo dele, dos quais ele recebe dados, e vários nós na camada acima dele, para os quais ele envia dados.
Uma inovação antiga
As redes neurais de aprendizado profundo são utilizadas atualmente em larga escala por conta da melhora na capacidade dos computadores e pela quantidade de dados disponíveis. Porém, elas já existem há muito tempo. Segundo o MIT, elas foram propostas pela primeira vez em 1944 por Warren McCullough e Walter Pitts, pesquisadores da Universidade de Chicago, que se mudaram para o MIT em 1952 como membros fundadores do primeiro departamento de ciências cognitivas. Conforme reportagem do ARS, em 1957 uma concepção inicial das redes neurais chamada perceptron foi criada por Frank Rosenblatt, da Cornell University, que com o apoio da Marina dos Estados Unidos, desenvolveu um sistema primitivo que podia analisar uma imagem de 20×20 e reconhecer formas geométricas simples.

Frank Rosenblatt trabalha em seu perceptron
O New York Times publicou à época que: “A Marinha revelou hoje o embrião de um computador eletrônico que espera ser capaz de andar, falar, ver, escrever, se reproduzir e ter consciência de sua existência”.
Bem, aparentemente eles estavam entusiasmados há 60 anos. Mas o fato é que, com a tecnologia disponível era limitada e as primeiras redes neurais tinham apenas uma ou duas camadas treináveis, se tornando matematicamente incapazes de modelar fenômenos complexos do mundo real. Seu uso passou por muitos altos e baixos entre os cientistas da computação ao longo dos anos, até que em 2012 explodiu através do artigo de uma rede neural apelidada de AlexNet, em homenagem ao pesquisador principal Alex Krizhevsky, da Universidade de Toronto, em que mostrou que redes mais profundas podem oferecer desempenho de alta performance se forem combinadas com amplo poder de computação e uma gigantesca quantidade de dados.
O poder de computação foi alcançando em parte pelo poder da indústria de games. As imagens complexas e o ritmo acelerado dos jogos eletrônicos de hoje exigem hardwares cada vez mais potentes e o resultado são as unidade de processamento gráfico (GPUs), que reúnem milhares de núcleos de processamento relativamente simples em um único chip, permitindo que as redes neurais de apenas uma ou duas camadas da década de 1960 se tornassem redes de 10, 15 e até 50 camadas de hoje. É a isso que se refere o “profundo” em “aprendizado profundo” – a profundidade das camadas da rede.
Hoje, o aprendizado profundo é responsável pelos sistemas de melhor desempenho em quase todas as áreas de pesquisa de inteligência artificial. Ocorreu então uma revolução do Deep Learning, com o Google adquirindo uma startup formada pelos autores do AlexNet e usando sua tecnologia como base para a função de busca de imagens no Google Fotos. Com base nas descobertas dos canadenses, outras empresas como Facebook, Apple, Amazon, Tesla aplicaram a tecnologia em novidades como sistema de reconhecimento facial, chips de Inteligência Artificial como no iOS, tecnologias de reconhecimento de voz como Alexa e Siri, se espalhando pelo mundo afora.
O funcionamento das redes neurais
Agora sabemos, de forma resumida, que as redes neurais artificiais são baseadas no que a ciência sabe sobre a estrutura e função do cérebro humano e no quanto consegue replicá-las como um sistema de computação.
Nessa estrutura, os padrões são introduzidos na rede neural pela camada de entrada e é comunicada a uma ou mais camadas ocultas presente na rede. As camadas ocultas recebem este nome somente por não constituírem a camada de entrada ou saída, são como camadas intermediárias. São nestas camadas que todo o processamento acontece por meio de um sistema de conexões dos chamados pesos e vieses.
A entrada é recebida, o neurônio calcula uma soma ponderada adicionando também o viés e de acordo com o resultado e uma função de ativação predefinida, ele decide se deve ser ‘disparado’ ou ativado. Posteriormente, o neurônio transmite a informação para outros neurônios conectados em um processo chamado “forward pass”. Ao final desse processo, a última camada oculta é vinculada à camada de saída que possui um neurônio para cada saída possível desejada, tornando, assim, a previsão possível. Por exemplo, o comando que um carro autônomo deve gerar no volante.

Estrutura básica de uma rede neural de 2 camadas. WI: Peso da conexão correspondente. Nota: A camada de entrada não é incluída na contagem do número de camadas presentes na rede.
Redes neurais mais profundas são modelos com mais camadas ocultas e isso significa mais neurônios e mais conexões entre os neurônios. E essa teia mais complexa de conexões, pesos e vieses, é o que permite que a rede neural “aprenda” as relações complicadas que estão ocultas nossos dados e obtenha insights de ações e tomadas de decisões, prevendo cenários futuros.
As Redes Neurais de Aprendizado Profundo permitiram grandes avanços de desempenho da Inteligência Artificial e uma notória variedade de aplicações. Ainda é um campo relativamente novo e é possível esperar um progresso muito mais rápido nesta área para os próximos anos, levando em consideração o avanço do Big Data e do poder de computação que melhora exponencialmente.


