

Conheça o MLOps, uma disciplina nova e em evolução derivada de DevOps e que permite às empresas escalar a produção de algoritmos de Machine Learning, tornando mais fácil e rápido solucionar problemas, testar experimentos e implantar novidades.
Uma prática recente surgiu no campo de Machine Learning, cujo nome é MLOps. Uma junção de Aprendizado de Máquina e Operações de Tecnologia da Informação. É uma disciplina para colaboração e comunicação entre equipes de dados e de TI para automação e produção de algoritmos em larga escala.

MLOps é uma intersecção entre Machine Learning , DevOps e Engenharia de Dados. Extraído do artigo no Medium de Manon Sikkes.
É possível dizer que MLOps é uma solução lógica para lidar com as dificuldades que surgem para colocar o Aprendizado de Máquina em produção nas empresas. Na engenharia de software existe DevOps, para garantir que o ciclo de desenvolvimento de software seja eficaz, envolvendo documentação, processo, padronização e governança da escrita do código, tornando mais fácil e rápido solucionar problemas, testar experimentos e implantar novas funcionalidades. O MLOps é exatamente isso, mas aplicado ao desenvolvimento de Machine Learning.
Um cientista de dados pode se perguntar por que se preocupar com MLOps, se já construiu os modelos e colocar isso em produção é trabalho da equipe de TI. Mas a realidade na maioria das empresas começando com Ciência de Dados é que os profissionais que projetam o algoritmo também implementam, o que torna válido um bom conhecimento de MLOps.
Além disso, é comum que profissionais ou equipes diferentes não tenham tanto conhecimento quanto ao pipeline desenvolvido e um esforço combinado no projeto de uma boa arquitetura de MLOps desde o início economiza tempo e evita muita dor-de-cabeça para todos os departamentos, agilizando o processo de implantação e mitigando os riscos de erros.

Diagrama com exemplo do ciclo de produção de Data Science
A Infraestrutura necessária
MLOps é um campo relativamente novo, ganhando força nos últimos dois anos. Ainda não existe uma padronização ou uma metodologia definida de como implementá-lo que se aplique a todas as escalas de produção de algoritmos. Porém, existem alguns requisitos necessários para uma implantação robusta de Machine Learning que são impossíveis de serem ignorados.
Para poder projetar uma infraestrutura para ML é importante ter clareza do que ela será capaz e onde pode facilitar o trabalho. Ela deve permitir o controle de forma flexível, escalando automaticamente de acordo com a necessidade, permitindo que o pipeline lide com diferentes quantidades de dados sem ter que ajustá-lo no futuro para ser mais eficiente ou escalar melhor.
É importante padronizar a implantação de pipelines, com uma estrutura para escrever código de forma fixa, tornando-o consistente entre os aplicativos. Essa padronização permite implantações automáticas: após o upload e a aprovação nos testes, o novo pipeline é implantado automaticamente na produção.

Representação visual de um pipeline de ML em Kubeflow Pipelines
Ter os dados armazenados no local onde são processados também minimiza os riscos de vazamento de informações. A integração precisa ser fácil com os pipelines de dados e armazenamento existentes, reduzindo a necessidade de migrações de dados, o que economiza tempo e dinheiro.
A infraestrutura também deve permitir a execução paralela de vários ambientes idênticos. Assim, a implantação ocorre sem a inatividade da aplicação, pois o pipeline de produção será executado em um ambiente próprio enquanto testes e ajustes podem ser feitos no ambiente de teste. O mesmo se aplica aos modelos retreinados em um pipeline: a infraestrutura deve permitir a troca apenas do modelo antigo pelo retreinado mantendo o resto no lugar sem interromper o fluxo de dados contínuos.
Outro ponto importante da infraestrutura é permitir o monitoramento e controle dos dados de itens como latência (o tempo que é adicionado pela infraestrutura ao executar uma solicitação), possibilitando a rápida identificação de erros e a permissão para ajustá-los. Isso deve ser acessível para todas as equipes envolvidas, tanto dados como TI.
O importante é entender que há muito a ser considerado ao projetar ou escolher uma infraestrutura de MLOps e nenhum caso de negócios é igual. Dependendo da situação, o foco poder ser em diferentes aspectos do ciclo de implantação. A infraestrutura de MLOps ideal deve se adaptar às necessidades, e não a empresa se adaptar à infraestrutura.
Boas práticas em MLOps
A infraestrutura é fundamental pois facilita os processos e ações de boas práticas do ciclo de MLOps dentro da empresa, permitindo a integração de times híbridos, com profissionais como cientistas de dados, engenheiros de ML e desenvolvedores.
Também vai tornar possível que o pipeline de dados se torne um pipeline de Machine Learning, já que é necessário a transformação dos dados para treinar os modelos. E aqui, o engenheiro de ML Cristiano Breuel explica que existem dois pipelines de ML distintos: o pipeline de treinamento e o pipeline de predição. O que eles têm em comum é que as transformações de dados que executam precisam produzir dados no mesmo formato, mas suas implementações podem ser muito diferentes. Por exemplo, o pipeline de treinamento geralmente é executado em arquivos em lote que contêm todas as features, enquanto o pipeline de predição geralmente é executado on-line e recebe apenas parte das features nas solicitações, buscando o restante de um banco de dados.

Os pipelines de ML conectam dados e código para produzir modelos e previsões
A infraestrutura também precisa permitir a prática do rastreamento de versões, para que os modelos sejam reproduzidos. Para desenvolver softwares tradicionais, versionar o código é suficiente. Em ML é preciso rastrear as versões do modelo, juntamente com os dados usados para treiná-lo.
Outra prática padrão do DevOps é a automação de testes, geralmente na forma de testes de unidade e testes de integração. A aprovação nesses testes é um pré-requisito para a implantação de uma nova versão. Os modelos de ML são mais difíceis de testar, porque nenhum modelo fornece resultados 100% corretos. Isso significa que os testes de validação precisam ser necessariamente de natureza estatística, em vez de ter um status simples de aprovação ou reprovação.
Assim como bons testes de unidade devem testar vários casos, a validação do modelo precisa ser feita individualmente para segmentos relevantes dos dados. Por exemplo, se o gênero for uma característica relevante é preciso rastrear métricas separadas para homens, mulheres e outros gêneros.
A outra questão é que o monitoramento de sistemas de produção é essencial para mantê-los funcionando bem. Em ML, o desempenho depende não apenas de fatores que podem ser controlados, mas os dados sobre os quais não se tem tanto controle. Então além de monitorar métricas padrão como latência, tráfego, erros e saturação, também é preciso monitorar o desempenho das previsões do modelo.
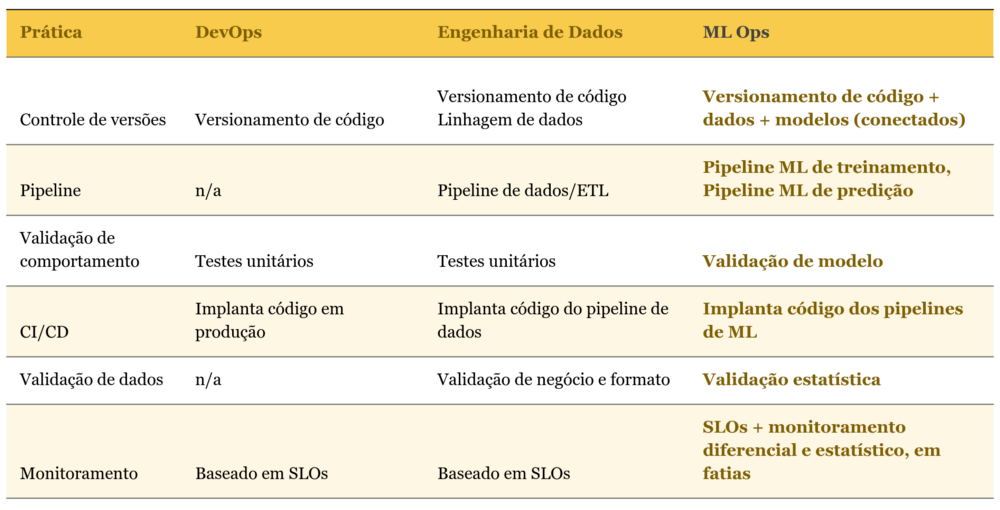
A tabela a seguir resume as principais práticas do MLOps e como elas se relacionam com as práticas de DevOps e Engenharia de Dados:
MLOps é uma disciplina nova, com ferramentas e práticas que ainda evoluirão com rapidez, então há muitas oportunidades no desenvolvimento e aplicação de técnicas de produção para ML.


