
Para iniciantes na área que desejam entender o básico, ou para quem não é diretamente envolvido em TI ou programação, aqui está um guia rápido pelos 10 principais algoritmos de Machine Learning usados pelos cientistas de dados.
Em Machine Learning, não há um algoritmo único que funcione melhor para todos os problemas. Não é possível dizer, por exemplo, que as redes neurais são sempre melhores que as árvores de decisão ou vice-versa. Existem muitos fatores em jogo, como o tamanho e a estrutura do seu conjunto de dados.
Por isso é necessário testar muitos algoritmos diferentes de aprendizado supervisionado para resolver um problema, enquanto se utiliza um conjunto de dados de espera para avaliar o desempenho e selecionar o vencedor.
Como analogia, para limpar a casa, é preciso escolher entre um aspirador, uma vassoura ou um esfregão. Depende da limpeza que você quer fazer, mas com certeza ninguém pegaria uma pá e começaria a cavar para tirar o pó do chão. Assim, os algoritmos utilizados para responder a uma pergunta devem ser apropriados para o problema.
1. Regressão Linear
A regressão linear é talvez um dos algoritmos mais conhecidos e bem compreendidos em estatística e aprendizado de máquina. É denominada dessa forma por ser uma reta traçada a partir de uma relação em um diagrama de dispersão. Essa reta resume uma relação entre os dados de duas variáveis e também pode ser utilizada para realizar previsões.
Sua origem vem da correlação linear, que é a verificação da existência de um relacionamento entre duas variáveis. Ou seja, dado X e Y, quanto que X explica Y. Para isso, a regressão linear utiliza os pontos de dados para encontrar a melhor linha de ajuste para modelar essa relação.
O resultado da regressão linear é sempre um número. É utilizada adequadamente quando o dataset apresenta algum tipo de tendência de crescimento/descrescimento constante.

Um exemplo de regressão linear é a relação de Preço x Oferta, onde a quantidade de produtos ofertados aumenta na medida em que o preço se eleva.
A regressão linear pode ser de dois tipos: regressão linear simples, onde é utilizada apenas uma variável independente; e regressão linear múltipla, onde múltiplas variáveis independentes são definidas. Esta última é utilizada em praticamente 100% dos casos em relação à regressão linear simples, pois um modelo útil de Data Science segue lógicas multivariadas.
2. Regressão Logística
A regressão logística é o método usado para problemas de classificação binária (problemas com dois valores de classe), utilizando conceitos de estatística e probabilidade. É um algoritmo que lida com questões e problemas de classificação, analisando diferentes aspectos ou variáveis de um objeto para depois determinar uma classe na qual ele se encaixa melhor.
A função logística parece um grande S e transformará qualquer valor no intervalo de 0 a 1. Isso é útil porque é possível aplicar uma regra à saída da função logística para ajustar valores para 0 e 1 e prever um valor de classe.
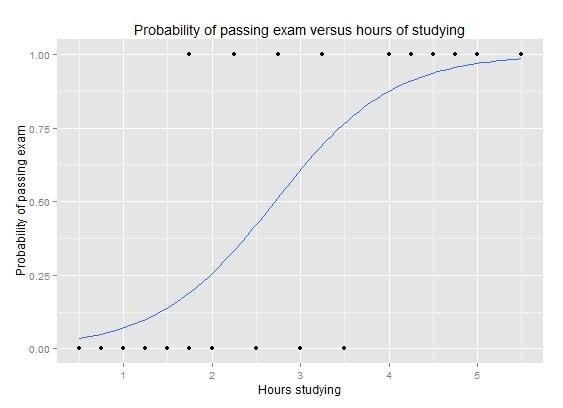
Regressão logística: Gráfico de uma curva de regressão logística mostrando a probabilidade de aprovação em um exame versus horas de estudo.
Há três modelos principais de regressão logística:
I. Regressão logística binominal
No modelo de regressão logística binominal, os objetos são classificados em dois grupos ou categorias. É quase um jogo entre “o que é” e “o que não é”. Por exemplo, o e-mail é spam ou não, a imagem é colorida ou não, a célula é cancerígena ou não.
II. Regressão logística ordinal
O modelo de regressão logística ordinal é diferente porque trabalha com o conceito de categorias ordenadas. Neste caso, os objetos são classificados em três ou mais classes que possuem uma ordem já determinada. Por exemplo, o desempenho do atleta é ruim, neutro ou excelente. Outro exemplo: o grau de satisfação do paciente com o tratamento é insatisfeito, satisfeito ou muito satisfeito.
III. Regressão logística multinomial
No modelo de regressão logística multinomial, os objetos são classificados em três ou mais categorias que não possuem ordem entre si. Por exemplo: este animal é um gato, um leão ou um tigre. Esta fruta é uma maçã, uma pera, uma manga ou um maracujá.
Em geral, as regressões podem ser usadas em aplicações como:
-
Pontuação de Crédito
-
Medindo as taxas de sucesso de campanhas de marketing
-
Prever as receitas de um determinado produto
-
Haverá um terremoto em um dia específico?
3. Análise Discriminante Linear
Regressão logística é um algoritmo de classificação tradicionalmente limitado a apenas problemas de classificação de duas classes. Se você tiver mais de duas classes, o algoritmo de Análise Discriminante Linear (LDA, na sigla em inglês) é a técnica de classificação linear preferida.
A representação da LDA é bastante direta. Consiste em propriedades estatísticas dos seus dados, calculados para cada classe. Para uma única variável de entrada, isso inclui:
-
O valor médio para cada classe
-
A variação calculada para todas as classes
As previsões são feitas calculando um valor diferenciado para cada classe e fazendo uma previsão para a classe com o maior valor. A técnica pressupõe que os dados tenham uma distribuição normal; portanto, é uma boa ideia limpar a base de dados removendo possíveis outliers. É um método simples e poderoso para classificar problemas de modelagem preditiva.
O LDA pode ser usado em qualquer problema que possa ser transformado em um problema de classificação. Exemplos comuns incluem reconhecimento de velocidade, reconhecimento facial, química, recuperação de imagens, biometria e bioinformática, para citar alguns.
Na visão computacional, o reconhecimento facial é considerado uma das aplicações mais populares. O reconhecimento é realizado representando os rostos usando grandes quantidades de valores de pixel. O LDA é usado para reduzir o número de recursos para preparar motivos para o uso do método de classificação. As novas dimensões são combinações de valores de pixel usados para criar um modelo.

4. Árvores de classificação e regressão
A representação do modelo da árvore de decisão é uma árvore binária. Cada nó representa uma única variável de entrada (x) e um ponto de divisão nessa variável (assumindo que a variável seja numérica).

Os nós das folhas da árvore contêm uma variável de saída (y) que é usada para fazer uma previsão. As previsões são feitas percorrendo as divisões da árvore até chegar a uma folha e gerar o valor da classe nessa folha.
As árvores são muito rápidas para fazer previsões. Eles também costumam ser precisas para uma ampla gama de problemas e não exigem nenhuma preparação especial para seus dados.
Como exemplo, vamos considerar este exemplo: uma amostra de 30 alunos de uma escola, com três variáveis: sexo (masculino ou feminino), classe (IX ou X) e altura (160 cm a 180 cm). Digamos também que dos 30 alunos, 15 deles jogam tênis no recreio. A partir disso, como podemos criar um modelo para prever quem vai jogar tênis durante o recreio? Neste problema, precisamos dividir os alunos que jogam tênis no recreio com base nas três variáveis à nossa disposição.
Nesse ponto entra a árvore de decisão. Ela dividirá os alunos com base nos valores das três variáveis e identificará a variável que cria os melhores conjuntos homogêneos de alunos (que são heterogêneos entre si). No quadro abaixo, é possível ver que a variável “sexo” é capaz de identificar os melhores conjuntos homogêneos em comparação com as variáveis “altura” e “classe”.

5. Naive Bayes
O algoritmo “Naive Bayes” é bastante utilizado para categorizar textos baseado na frequência das palavras usadas e assim pode identificar se determinado e-mail é um spam ou também se uma notícia é sobre tecnologia, política ou esportes… ou ainda pode verificar um pedaço de texto que expressa emoções positivas ou emoções negativas.
Por ser muito simples e rápido, possui um desempenho relativamente maior do que outros classificadores. Além disso, o Naive Bayes só precisa de um pequeno número de dados de teste para concluir classificações com uma boa precisão.

A principal característica do algoritmo, e também o motivo de receber “naive” (ingênuo) no nome, é que ele desconsidera completamente a correlação entre as variáveis. Ou seja, se determinada fruta é considerada uma “Laranja” se ela for “Amarela”, “Redonda” e possui “8 cm de diâmetro”, o algoritmo não vai levar em consideração a correlação entre esses fatores, tratando cada um de forma independente.
6. KNN(K-Nearest Neighbors)
KNN é um algoritmo que classifica novos dados com base em uma medida de similaridade entre seus “vizinhos” mais próximos, ou seja, aqueles que têm características semelhantes às suas.
Ele pressupõe que itens semelhantes estão próximos um dos outros, então tenta encaixar o dado em questão nos conjuntos de seus vizinhos. O que muda aqui é o valor de K, a primeira letra da sigla, que vai ser a distância entre o dado e os seus vizinhos. Quanto menor a distância, mais chance de serem mais semelhantes. Portanto, dependendo de como o valor K é calculado, podem ser os 3 vizinhos mais próximos ou até os 50 vizinhos mais próximos.
Por exemplo: se tenho uma laranja e quero saber se ela é fruta ou legume. O algoritmo vai checar que os 50 itens ao redor da laranja são 30 maçãs e 20 cenouras… então vai definir laranja como fruta, pois a maioria dos vizinhos mais próximos são frutas também. Mas, se o algoritmo considerar somente os 5 vizinhos mais próximos, e eles são 4 cenouras e 1 maçã, ele vai classificar a laranja como legume.

Um dos seus usos é para serviços de recomendação, como produtos da Amazon, filmes na Netflix, e vídeos no YouTube. No entanto, podemos ter certeza de que todos eles usam meios mais eficientes de fazer recomendações devido ao enorme volume de dados que processam, porque uma desvantagem do KNN é a lentidão à medida que o volume de dados aumenta, tornando uma escolha impraticável em ambientes em que as previsões precisam ser feitas rapidamente.
7. LVQ: Learning Vector Quantization
O LVQ é um método de aprendizado baseado em protótipo, em que eles são usados para representar diferentes classes em um conjunto de dados.
Conforme explica o cientista de dados Thomas Nijman, cada protótipo é descrito como um ponto no espaço de variáveis. Os novos pontos de dados (desconhecidos) recebem a classe do protótipo mais próximo deles. Para que o “mais próximo” faça sentido, uma medida de distância deve ser definida.
O LVQ é semelhante ao KNN, levando vantagem em não precisar considerar todo o conjunto de dados disponível, reduzindo os requisitos computacionais necessários para ser executado.

8. SVM: Support Vector Machine
O SVM também é amplamente utilizado em objetivos de classificação. Porém, seu objetivo é encontrar um hiperplano em um espaço N-dimensional (N = o número de variáveis) que classifica de forma diferente os pontos de dados.
Conforme explica Rohith Gandhi, hiperplanos são limites de decisão que ajudam a classificar os pontos de um conjunto de dados. Os dados que caem em ambos os lados do hiperplano podem ser atribuídos a diferentes classes. Além disso, a dimensão do hiperplano depende do número de variáveis. Se o número de recursos de entrada for 2, o hiperplano será apenas uma linha. Se o número de recursos de entrada for 3, o hiperplano se tornará um plano tridimensional. Torna-se difícil imaginar quando o número de recursos excede 3.

Hiperplanos possíveis

Para separar as duas classes de dados, existem muitos hiperplanos possíveis que podem ser escolhidos. O objetivo é encontrar um plano que tenha a distância máxima entre os pontos das duas classes. Essa maximização da distância da margem fornece algum reforço para que dados futuros possam ser classificados com mais confiança.

Hiperplanos 2D e 3D no espaço de variáveis
Os vetores de suporte são pontos de dados que estão mais próximos do hiperplano e influenciam sua posição e orientação. Usando esses vetores de suporte, maximizamos a margem do classificador, na medida em que a exclusão dos vetores de suporte alterará a posição do hiperplano. Esses são os pontos que nos ajudam a criar um modelo de SVM.

Na prática, um algoritmo de otimização é usado para encontrar os valores dos coeficientes que maximizam a margem. Assim, o SVM pode ser um dos mais poderosos classificadores em machine learning.
9. Random Forest
Os algoritmos Random Forest são criados por várias árvores de decisão, geralmente treinados com o método de bagging, cuja ideia principal é que a combinação de modelos aumenta o resultado final.
Um classificador de floresta aletória tem todos os hiperparâmetros de uma árvore de decisão e também todos os hiperparâmetros de um classificador de bagging, para controlar a combinação de árvores. Ao invés de construir um classificador bagging e passá-lo para um classificador de árvore de decisão, é mais conveniente utilizar a classe da floresta aleatória.
Um bom exemplo é apontado por Niklas Donges: imagine que um rapaz chamado Andrew deseja decidir para onde deve viajar de férias. Ele pede informações para vários conhecidos. Primeiro, encontra com um amigo que o pergunta para onde ele já viajou e se ele gostou ou não. Baseado nestas respostas, ele dá algumas sugestões para Andrew.
Esta é uma abordagem típica de árvores de decisão. O amigo criou regras para guiar sua decisão sobre o que recomendar, a partir das respostas de Andrew.
Depois disto, Andrew começa a pedir sugestões para mais amigos e eles fazem várias perguntas diferentes antes de darem alguma sugestão. Então, ele escolhe os lugares que receberam mais recomendações, o que é uma abordagem típica de florestas aleatórias.
Nos negócios, o Random Forest é utilizado em muitas áreas. Nos bancos para detectar clientes que irão usar os serviços bancários mais frequentemente que outros e pagar suas dívidas em dia. No setor financeiro é utilizado para determinar o desempenho futuro de uma ação. Na área de saúde é utilizado para identificar a correta combinação de componentes em medicina e também para analisar o histórico médico de um paciente para identificar doenças. Já nos e-commerces pode ser utilizado para determinar se um cliente irá gostar do produto ou não, fazendo recomendações dos mais alinhados ao seu perfil e que, provavelmente, façam mais sentido comprar.
10. Boosting
Basicamente, o Boosting é um algoritmo que converte uma aprendizagem fraca em uma aprendizagem forte, como mostra esse artigo do Analytics Vidhya.
De forma prática, vamos pegar o exemplo da classificação de um email como SPAM. A abordagem inicial pode usar alguns critérios, como:
-
Se o e-mail tem apenas um arquivo de imagem (imagem promocional) – É um SPAM
-
Se o email tem apenas links – É um SPAM
-
Se o corpo do email consiste na frase como “você ganhou um dinheiro premiado de $ xxxxxx” – É um Spam
-
Se o email é do domínio “Analyticsvidhya.com” – Não é um SPAM
-
Se o email é de uma fonte conhecida – Não é um SPAM
Porém, essas regras não são fortes o suficiente para classificar corretamente um e-mail. Por isso são chamadas de aprendizagem fraca. Para converter em aprendizagem forte, se combina a previsão de cada aprendizagem fraca com outras formas, como usar média e média ponderada e considerar a previsão que tiver mais votos.
No exemplo foram definidas cinco aprendizagens fracas, onde três são votadas como spam e duas são votados como “não spam”. Nesse caso, por padrão, podemos considerar um e-mail como spam porque temos mais votos para spam. Assim, o boosting combina o aprendizado fraco (também conhecido como base de aprendizagem) para formar uma regra forte.
Para encontrar uma regra fraca, aplicamos algoritmos com uma distribuição diferente, gerando uma nova regra de previsão fraca. Após muitas interações, o algoritmo de boosting combina essas regras fracas em uma única regra de predição forte.


