

Sistemas de recomendação são capazes de sugerir músicas, vídeos e produtos que estão de acordo com nossas preferências. Descubra como eles são capazes de prever com tanta precisão gostos pessoais que nem nós mesmos conhecíamos.
O portal Towards Data Science dissecou o funcionamento dos sistemas de recomendação. Eles já são parte integrante do dia a dia da vida digital, presentes em serviços como Netflix (para recomendação de filmes e séries), Amazon (livros e produtos), Spotify (músicas) e YouTube (vídeos).
Esses sistemas são importantes diante da enorme demanda por conteúdo personalizado dos consumidores modernos. Para exemplificar como funcionam diferentes mecanismos de recomendação, o pesquisador James Le apresentou quatro abordagens utilizadas para recomendação de filmes.
Conjunto de dados
Como a maioria dos projetos de Data Science, ele começa com o levantamento de um conjunto de dados. No caso, foi utilizado o MovieLens, um dataset comumente utilizado para criação de sistemas de recomendação de filmes. James Le usou uma versão com 1.000.209 classificações, sobre 3.900 filmes, dadas por 6.040 usuários anônimos.
Em primeiro lugar, o pesquisador processou os dados e realizou algumas análises exploratórias para entender as características mais interessantes do conjunto de dados.

A visualização da nuvem de palavras com os títulos dos filmes permite observar que há várias franquias nesse dataset, em virtude da prevalência de termos como “II” e “III”. Além disso, algumas palavras recorrentes são “dia”, “amor”, “vida”, “tempo”, “noite”, “homem”, “morto” e “americano” (na nuvem, os termos correspondem aos títulos originais, em inglês). Além disso, as classificações obedeceram à seguinte distribuição:

Aparentemente, os usuários foram bastante generosos em suas classificações. Em uma escala de 5, a avaliação média foi 3,58 e metade dos filmes teve nota 4 ou 5. Por fim, os principais gêneros classificados foram drama, comédia, ação, suspense e romance.

Feita uma análise inicial dos dataset, James Le apresentou quatro sistemas de recomendação que poderiam ser aplicados aos dados:
-
Filtragem baseada em conteúdo
-
Filtragem colaborativa baseada em memória
-
Filtragem colaborativa baseada em modelos
-
Deep Learning/Rede Neural
Filtragem baseada em conteúdo
A recomendação baseada em conteúdo é fundamentada na similaridade dos itens recomendados. A ideia básica é que, se um usuário gosta de um determinado item, também gostará de um item semelhante. Ela funciona bem quando é fácil determinar as propriedades de cada item – e logo, sua semelhança com outros itens.
Esse sistema trabalha a partir de dados fornecidos pelos usuários, como as classificações de filmes da MovieLens. Na medida em que os usuários fornecem mais informações, o mecanismo se torna mais preciso.
Resumidamente, o sistema calcula matematicamente a importância dos termos utilizados para descrever os itens. Por exemplo, um usuário poderia buscar os termos “os resultados dos últimos jogos do futebol europeu” no Google. Embora os termos “os” e “dos” sejam seguramente mais mencionado nas páginas indexadas, a importância do termo “jogos do futebol” é muito maior. Assim, uma equação pondera o efeito de palavras de alta frequência na determinação da importância de um item.
Em seguida, outros cálculos matemáticos determinam a proximidade entre diferentes itens, conforme o gráfico a seguir. A sentença 2 tem maior probabilidade de usar o termo 2 do que o termo 1. O contrário se aplica à sentença 1.

Assim, James Le criou um mecanismo de recomendação baseado em conteúdo que calculou a similaridade entre filmes a partir dos gêneros com os quais foram descritos. Ou seja, ele sugere obras que são semelhantes a um determinado filme a partir de seu gênero. O pesquisador conseguiu os seguintes resultados de recomendação:
“Gênio Indomável” (1997)

“Toy Story” (1995)

“O Resgate do Soldado Ryan” (1998)

As recomendações parecem coerentes, não? Para “Gênio Indomável”, o sistema recomendou outros dramas, para “Toy Story”, animações, infantis ou comédias, e para “O Resgate do Soldado Ryan”, outras obras de ação, thriller ou guerra.
As vantagens da recomendação baseada em conteúdo são:
-
Não há necessidade de dados sobre outros usuários.
-
Ela consegue recomendar para usuários com gostos peculiares.
-
Pode recomendar itens novos e impopulares.
-
Pode fornecer explicações e listar as características que levaram à recomendação de um item (no caso, gêneros de filmes).
Já as desvantagens da abordagem são:
-
Encontrar as características apropriadas é difícil.
-
Ela não recomenda itens fora do perfil das preferências do usuário.
-
Não é possível explorar a qualidade do julgamento dos usuários.
Filtragem colaborativa baseada em memória
A recomendação via filtragem colaborativa baseada em memória é fundamentada pelo comportamento dos usuários no passado. Em outras palavras, é baseada na similaridade de preferências, gostos e escolhas entre usuários ao longo do tempo. Ela analisa o quão semelhante o gosto de um usuário é para o outro e faz recomendações com base nisso.
Por exemplo, se o usuário A gosta dos filmes 1, 2, 3 e o usuário B gosta dos filmes 2, 3, 4, eles aparentam ter interesses semelhantes. Logo, o usuário A é propenso a gostar do filme 4 e o usuário B deve gostar do filme 1. Este é um dos algoritmos mais comumente utilizados, pois não depende de nenhuma informação adicional.
Em geral, a filtragem colaborativa é a grande responsável pelos mecanismos de recomendação. Uma de suas propriedades mais interessantes é que ela é capaz de aprender sozinha quais recursos deve utilizar.
Há dois principais tipos de algoritmos de filtragem colaborativa:
-
Filtragem colaborativa usuário-usuário: O sistema encontra usuários parecidos com base na similaridade e recomenda filmes que os primeiros usuários parecidos escolheram no passado. O algoritmo é muito eficaz, mas requer tempo e recursos, pois necessita que todas as informações pareadas sejam computadas, o que leva tempo.
-
Filtragem colaborativa item-item: É semelhante ao algoritmo anterior, mas, ao invés de encontrar usuários parecidos, tenta encontrar filmes parecidos – a partir das escolhas dos usuários. Esse algoritmo consome muito menos recursos. O sistema não precisa analisar todos os índices de similaridade entre usuários, mas sim a similaridade entre filmes – o que representa um número menor de itens ao longo do tempo.
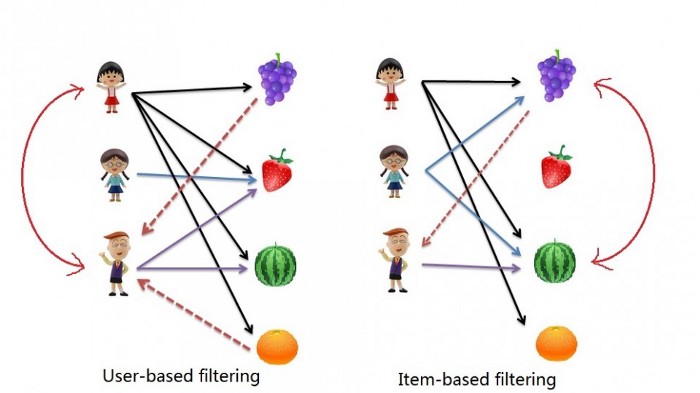
Em ambos os cenários, cálculos matemáticos determinam a similaridade – entre usuários ou itens.
James Le afirma que algumas das vantagens da filtragem colaborativa são a facilidade de implementação e a qualidade preditiva razoável. No entanto, há algumas desvantagens nessa abordagem:
-
Como um carro que demora para esquentar, esse sistema enfrenta dificuldades quando novos usuários ou itens são inseridos.
-
É difícil encontrar usuários que tenham avaliado os mesmos itens.
-
Ela tende a recomendar itens populares.
Filtragem colaborativa baseada em modelos
Para resolver alguns problemas da abordagem anterior, há a filtragem colaborativa baseada em modelos. Segundo James Le, ela começa a partir de uma técnica chamada “redução da dimensionalidade”. Em linhas gerais, ela se trata de um tratamento dos dados brutos – como aqueles utilizados na filtragem colaborativa baseada em memória, descrita anteriormente.
As dimensões são “reduzidas” porque essa técnica permite encontrar padrões de gostos e preferências, o que, por sua vez, permite identificar correlações, remover dados incomuns, interpretar e visualizar dados, além de armazená-los com mais facilidade.
Mais do que isso, essa técnica permite com que o sistema aprenda as preferências dos usuários e os atributos dos itens avaliados e, então, crie previsões sobre classificações ainda desconhecidas. Tudo isso por meio de um complexo método matemático.
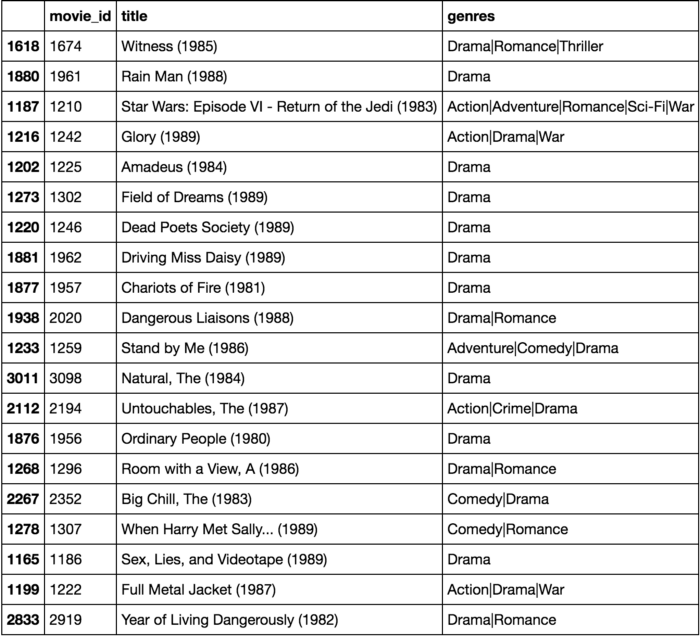
Para demonstrar o funcionamento, James Le recomendou 20 filmes para um usuário aleatório que havia dado boas notas para filmes de comédia, drama e ação. Embora o pesquisador não tenha usado os gêneros dos filmes como parâmetro para recomendação, a lista captou exatamente os gêneros preferidos do usuário – o que mostra a boa capacidade preditiva do modelo.
Deep Learning/Rede Neural
Redes neurais são programas de computador que procuram aprender de uma maneira semelhante ao cérebro humano. Assim, Deep Learning é entendido como a utilização massiva dessas redes neurais para gerar programas com camadas profundas de aprendizado.
A abordagem mais sofisticada para sistemas de recomendação é baseada em Deep Learning. James Le utilizou o conjunto de dados da MovieLens para treinar exaustivamente um modelo capaz de prever as classificações que um usuário aleatório daria para um filme aleatório. É um processo que toma tempo e vastos recursos computacionais. Os resultados foram estes:

O pesquisador avalia que esse modelo teve um desempenho melhor do que todas as outras abordagens. Porém, ele afirma que esse desempenho sempre pode ser melhorado com a utilização de mais e mais camadas de aprendizado – não à toa, a utilização de Deep Learning tem se tornado cada vez mais comum em projetos de Data Science.
Resumidamente, esses são os mecanismos por trás dos sistemas de recomendação que criam opções tailor-made e oferecem experiências personalizadas no atual mundo contemporâneo. Uma vez que tais sistemas se tornam cada vez mais populares, eles devem ser uma das prioridades de empresas que desejam ser competitivas e eficientes para seus consumidores.


