

É impossível falar de Data Science, nos negócios ou em qualquer outra área, sem pensar em estatística.
Os métodos de análise dos dados disponíveis na era do Big Data, em geral, são baseados em testes estatísticos. Para quem não sabe sobre o assunto, vale ter em mente alguns fundamentos básicos.
Uma aplicação central da estatística é reconhecer padrões de comportamento e atitude. Fica fácil com alguns exemplos. Se você fosse analisar estatisticamente as unidades da rede de uma escola de ensino de línguas, quais padrões seriam importantes?
Um deles seria a frequência. Por exemplo, seria possível identificar se há diferença de média de faturamento entre unidades novas e antigas. Outra possibilidade é montar agrupamentos das unidades, que detectariam as melhores escolas em venda e as melhores em ensino. Associações poderiam entender que unidades em bairros centrais faturam mais do que aquelas em bairros periféricos. E relações de causalidade possibilitariam concluir que quanto maior o preço das mensalidades, menor as vendas.
Variáveis
Em estatística, é muito comum observar os dados por uma relação entre variáveis: como uma afeta a outra. A variável dependente é o fenômeno que estamos tentando explicar. Variável independente são as possíveis explicações do fenômeno. Ou seja, você analisa como as variáveis independentes estão afetando a variável dependente.
Quando falamos de negócios, como essa relação de variáveis se aplica? Basicamente, as variáveis independentes explicam duas importantes variáveis dependentes: comportamento e atitude.
O comportamento é algo observável e contável. Observe os seguintes exemplos.
-
Preço (VI) explica intenção de compra (VD)
-
Promoção (VI) explica acessos ao site (VD)
-
Mídia (VI) explica fluxo na loja (VD)
-
Boca a boca (VI) explica ligação no call Center (VD)
-
Speech do vendedor (VI) explica venda (VD)
-
Prontidão de contato (VI) explica agendamentos de test drive (VD)
A atitude engloba elementos distintos como pensamento, sentimento e predisposição. Para ser identificada, ela requer declaração. Alguns exemplos:
-
Qualidade (VI) explica satisfação (VD)
-
Recall (VI) explica trial (VD)
-
Força de marca (VI) explica disposição a pagar mais (VD)
-
Preço (VI) explica intenção de compra (VD)
-
Identificação (VI) explica recomendação (VD)
Já deve ter ficado claro que a gestão altera as variáveis independentes. Não temos controle sobre o fluxo da loja (VD), mas podemos investir em mídia (VI). Não temos controle sobre a satisfação dos nossos clientes (VD), mas podemos investir na qualidade dos serviços (VI).
É a junção de todas as variáveis dependentes (comportamentos e atitudes) que vai resultar nos melhores clientes. Por exemplo, um cliente que tenha alta intenção de compra, fluxo freqüente na loja e disposição a pagar mais, merece uma pontuação mais alta. Essa pontuação é o Lead Score.
Como escolher as melhores variáveis para compor o seu Lead Score? Falaremos melhor sobre a modelagem dessas questões em posts futuros. Porém, já vale antever que o histórico da empresa nos conta sobre as variáveis relevantes. O primeiro passo é testar com poucas variáveis, começar com uma complexidade menor, até alcançar um ajuste mais completo.
Lead Score
Uma vez identificadas as variáveis dependentes que aumentam as chances de identificar um cliente em potencial, é possível criar um Lead Score – ou seja, uma pontuação para cada cliente potencial.
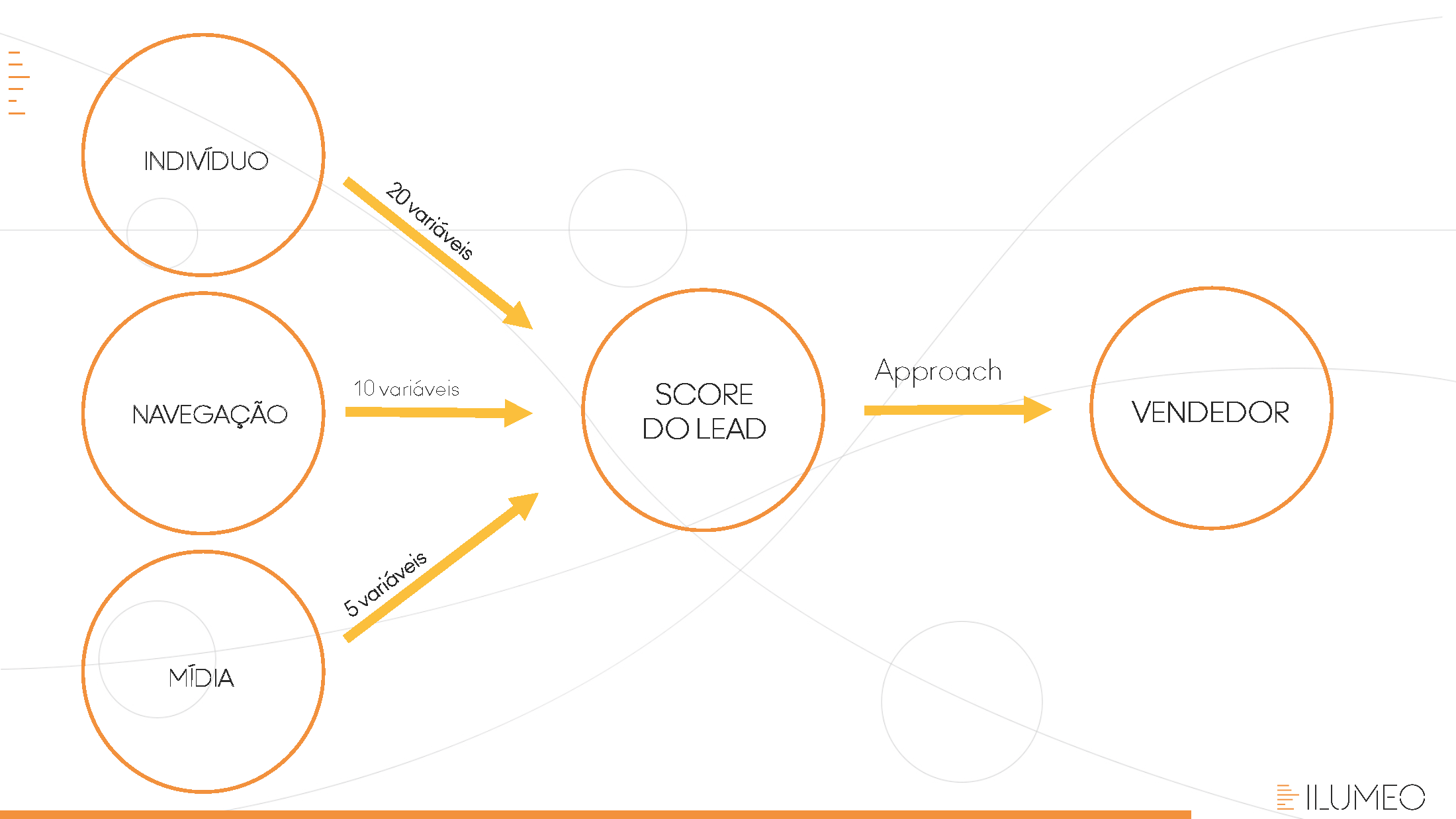
No entanto, a meta principal não deve ser apenas ter uma pontuação alta – ou seja, aproveitar os clientes que apresentem números elevados no Lead Score. Tão importante quanto isso é ter vendedores que saibam fazer o approach adequado à pontuação daquele cliente.
Hipóteses
Agora que falamos sobre variáveis, é muito provável que você esteja se perguntando: como estabelecer as hipóteses para entender as relações entre as variáveis? Temos algumas sugestões.
Ir além da própria cabeça. Uma pesquisa qualitativa interna, como uma conversa com um vendedor, pode fornecer informações preciosas de quem vive o cotidiano do negócio. Sempre há dados secundários disponíveis, muitas vezes gratuitos, que podem dar insights. Observar os concorrentes por meio de benchmarking nunca é demais. E, claro, ler os artigos científicos mais recentes da área é fundamental.
Há inúmeras revistas científicas em todas os campos do conhecimento e, sem dúvida, alguém já estudou aquela hipótese que surgiu na conversa do bar. Ainda não está no mindset do mercado buscar respostas na academia, mas é um desperdício não dar uma olhada no que está sendo feito em pesquisa científica.
Entender as principais características de uma hipótese. Ela deve ser concreta, averiguada por meio de variáveis mensuráveis. Fuja de conceitos abstratos como “de que maneira a produtividade afeta o clima organizacional?”. Além disso, a hipótese deve ser exata e precisa. Exatidão é o nível de proximidade da mensuração do verdadeiro valor e em que medida corresponde à realidade. Precisão é a conformidade das mensurações (em que medida o instrumento de mensuração está calibrado).
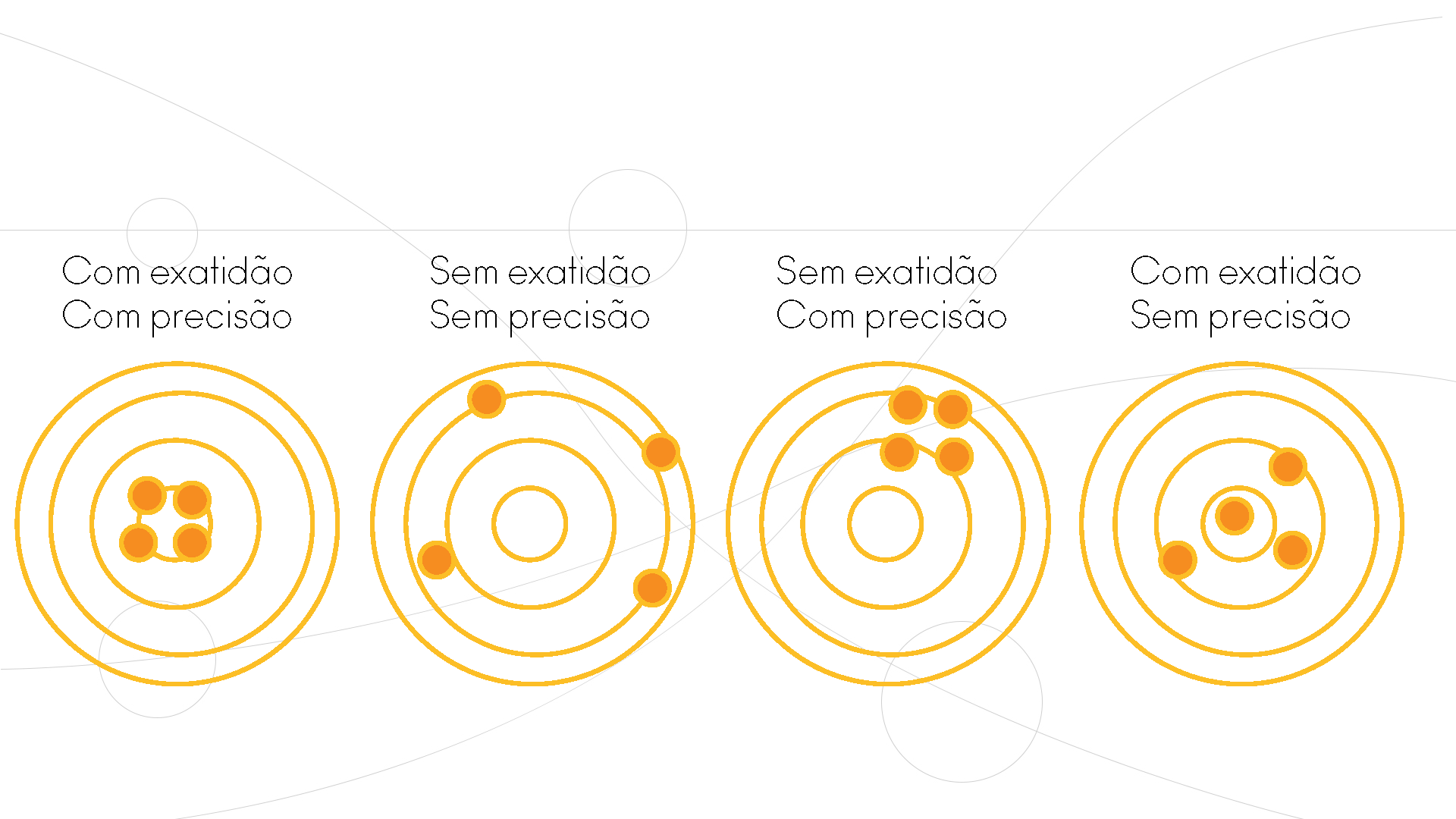
Por fim, é necessário parcimônia no estabelecimento de hipóteses. Como falamos, comece com poucas variáveis. E tenha certeza do fundamento teórico que levou à escolha dessas variáveis.
Para saber mais
Tudo o que foi descrito neste artigo foi apresentado no curso Data Lab – Entendendo a Ciência por Trás dos Dados, uma parceria entre a Ilumeo e a Sandbox. Quer participar das próximas edições do curso ou saber mais sobre Data Science? Cadastre o seu e-mail no campo abaixo e vamos aprender juntos.


