

Quando se analisa a aplicação de modelos de causalidade no mundo dos negócios é fundamental ter em mente que teoria e prática não devem ter separação. Aliás, muito pelo contrário. É a partir da teoria que montamos modelos e, então, aplicamos métodos para pesquisar em campo fenômenos sociais.
Em outras palavras, é necessário entender a interação entre as variáveis quando se quer explicar fenômenos. E qual é o ponto de partida para imaginar como interagem as variáveis? Exato, teoria.
Um exemplo prático. No momento em que lê este texto, você preferiria tomar uma Coca-Cola ou um café? Provavelmente, você já tem uma escolha em mente. No entanto, podemos adicionar uma variável nesta decisão. Se ambas as opções estiverem quentes, você continuaria com a mesma escolha? E se ambas estiverem geladas?
É muito provável que, se ambas estiverem geladas, você prefira a Coca-Cola. Caso estejam quentes, há maior probabilidade de que você prefira o café. A variável “temperatura” tem grande peso em um modelo que tenha o intuito de prever qual bebida será escolhida pelo indivíduo pesquisado. Porém, só sabemos a importância dessa variável porque dominamos a teoria – ou seja, temos conhecimento sobre a maneira como essas bebidas são usualmente consumidas.
No livro “O Sinal e o Ruído”, o economista Nate Silver dá um exemplo que ajuda a entender bastante a importância da teoria na definição de modelos preditivos. O gráfico a seguir mostra uma curva que relaciona a idade de um jogador de beisebol com sua performance nas quadras. Em média, um jogador de 29 anos está no auge de seu desempenho, que aumenta após os 18 anos e cai na medida em que se aproxima dos 40.
.


Entretanto, essa curva representaria com propriedade todos os jogadores de beisebol? Com certeza, não. Há diversas variáveis envolvidas na relação entre a idade do jogador e sua performance. Por exemplo, a posição em que o jogador atua. Há posições favorecidas pela idade precoce, enquanto outras dependem da experiência do indivíduo em campo. Ou seja, variáveis como “idade” e “performance” pouco tem a dizer se não forem acompanhadas de uma boa teoria.
Por isso, não acreditamos em obras como “The End of Theory”, de Richard Bookstaber, e na crença de que a existência massiva de dados suplantará o método científico – como já foi sugerido por Chris Anderson. Embora os dados sejam fundamentais em qualquer interpretação, não é possível explicar um fenômeno social somente com métodos quantitativos. A teoria é essencial.
Exemplos de modelos causais cientificamente validados
Agora que falamos um pouco sobre interação entre variáveis e a importância da teoria, vamos olhar dois exemplos de modelos causais cientificamente validados: comportamento planejado e satisfação.

Em 1981, Richard Bagozzi já apresentava um modelo que demonstrava como nossos valores orientam nossos comportamentos. No jargão do marketing, diante de uma compra em potencial, acessamos marcas sintonizadas com nossos valores. Esse mesmo tipo de modelo evoluiu e pode ser aplicado para explicar um número infindável de comportamentos.
Para colocar em um exemplo do mundo real, como poderíamos medir a atitude de um indivíduo em relação a uma propaganda e a possível intenção de compra após assistir ao anúncio? Um modelo causal entenderia quais variáveis afetam a atitude do indivíduo em relação ao vídeo – por exemplo, emoções, atributos da propaganda e serviços oferecidos pelo anunciante. A atitude em relação ao vídeo, por sua vez, pode explicar a imagem da marca e a intenção de comportamento do indivíduo.
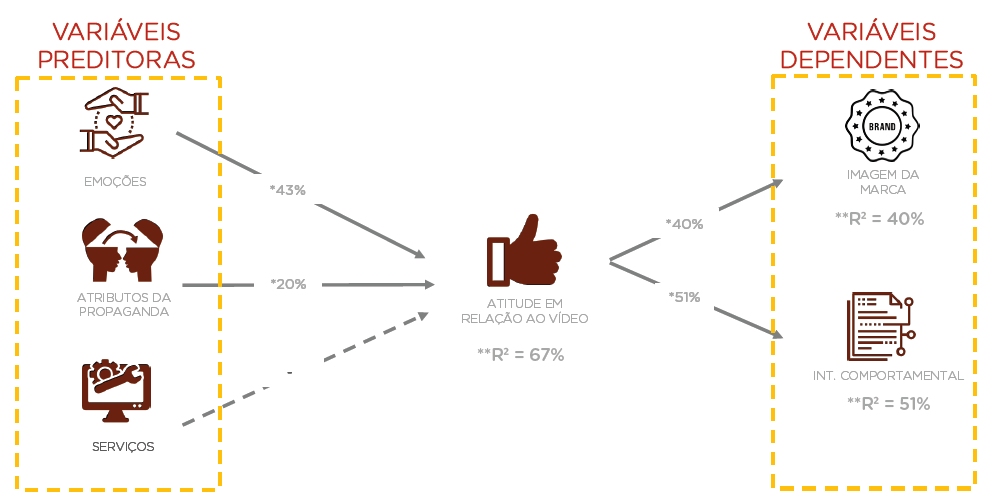
No exemplo, as porcentagens explicam os pesos de cada item na composição da atitude. O R² é a medida de ajuste do modelo. Ou seja, o quanto conseguimos explicar da atitude em relação ao vídeo com os itens da regressão.
Satisfação
Já falamos neste blog sobre a imprecisão do NPS como uma medida de satisfação. Em suma, ele não é um índice confiável porque representa somente a variável dependente – ou seja, a probabilidade de recomendação daquele produto ou serviço. No entanto, quais seriam as variáveis preditoras que culminariam naquela recomendação? O NPS não é um modelo robusto o suficiente para dar conta dessa questão.
Em outras palavras, uma busca no Google sobre satisfação traria o NPS como uma boa alternativa. Já uma busca no Google Acadêmico apresentaria verdadeiros modelos sobre satisfação – tais como o American Customer Satisfation Index (ACSI). Validado cientificamente e usado pelo governo norte-americano, o modelo observa como a qualidade percebida, o valor percebido e as expectativas do consumidor predizem a satisfação. Bem mais robusto, não?

Conceitos para evitar distorção de causalidade
Já sabemos que a teoria é fundamental no estabelecimento das possíveis variáveis preditoras que apresentam efeito no modelo que estamos estudando. Os detalhes estatísticos serão desvendados em posts futuros, mas já vale a pena ter em mente alguns conceitos que podem evitar uma relação de causalidade errônea.
A multicolinearidade se dá quando as variáveis analisadas se comportam de maneira muito similar. Por exemplo, ao estudar um modelo que preveja as variáveis que culminam na compra de um produto, os pedidos de compras acompanham paralelamente as compras propriamente ditas. Embora os pedidos sejam uma variável que prediz corretamente quando as compras acontecem, isso não nos diz muito.


Enquanto outras variáveis são capazes de explicar a ocorrência de compras, a partir do momento em que os pedidos de compras são acrescentados no modelo, eles predizem com tanta força o resultado que eliminam os efeitos das outras variáveis.
A temporalidade é outro conceito central que merece atenção e está completamente atrelado ao conhecimento teórico que se tem sobre o fenômeno estudado. Há mais tweets sobre Bitcoin quando o preço da moeda diminui ou o preço do Bitcoin varia conforme a discussão sobre o assunto no Twitter? É razoável imaginar que a oscilação de preço é o fator determinante na repercussão nas mídias sociais.
Por fim, a correlação espúria é outro conceito estatístico fundamental. Ele acontece quando não há relação de causalidade, mas existe correlação. Uma anedota famosa é aquela que correlaciona o número de picolés vendidos na praia ao número de afogamentos de banhistas. Quanto mais picolés são vendidos, maior o número de afogamentos. Estariam os picolés causando afogamentos? Faria mais sentido imaginar que são os dias de calor que têm efeito sobre ambas as variáveis.
Para saber mais
Tudo o que foi descrito neste artigo foi apresentado no curso Data Lab – Entendendo a Ciência por Trás dos Dados, uma parceria entre a Ilumeo e a Sandbox. Quer participar das próximas edições do curso ou saber mais sobre Data Science? Cadastre o seu e-mail no campo abaixo e vamos aprender juntos.


