
O site educativo DataOptimal comentou recentemente sobre as inúmeras aplicações da Data Science na resolução de problemas de negócios. Dentre elas, reduzir custos, aumentar receita, melhorar a experiência do consumidor e por aí vai. Para exemplificar o passo a passo de um projeto de Data Science, o site sugeriu um modelo de Machine Learning construído para prever churn. Em outras palavras, um modelo preditivo que identifica quando um cliente está prestes a abandonar a empresa, de maneira que uma ação de retenção possa ser realizada.
O case se trata de uma hipotética empresa de telecomunicações que gostaria de melhorar seus negócios por meio da Data Science. Como funciona? Em primeiro lugar, essa empresa define qual problema está tentando resolver. No caso, ela identificou que é cinco vezes mais caro adquirir novos clientes do que reter os atuais. Logo, o problema é aumentar a taxa de retenção de clientes para diminuir custos. Uma possível solução de Data Science é construir um modelo de Machine Learning para prever o churn. Depois, esse modelo é avaliado por meio de métricas de negócios e testes estatísticos e, por fim, é implementado.
Escolha do modelo
Uma vez que o problema está bem definido, o cientista de dados vai eleger uma técnica estatística para analisar os dados. Elas são escolhidas segundo a natureza dos dados e as relações entre eles. Uma vez que o objetivo é prever se houve churn (“sim” ou “não”), um modelo de classificação como a regressão logística é adequado.
Preparo dos dados
O fluxo de trabalho para preparo dos dados varia projeto a projeto. No caso do exemplo, é necessário: 1) importar os dados; 2) revisar; 3) limpar; e 4) dividir. Uma linguagem de programação muito robusta para análises estatísticas é o R. Logo, o primeiro passo é importar os dados dos consumidores para o software que roda essa linguagem. Em seguida, o cientista de dados revisa quais variáveis (ou características) do consumidor foram coletadas. No caso, a variável que queremos prever é o churn. Veja a seguir um exemplo da tela de revisão no R.

Na sequência, os dados são limpos. Por exemplo, variáveis numéricas podem ser transformadas em variáveis nominais, se for interessante para a análise pretendida. Variáveis ausentes e dados desnecessários são eliminados. Por fim, os dados são divididos em dois conjuntos: “treinamento” (utilizado para treinar o modelo) e “teste” (utilizado para averiguar se o treinamento funcionou). Esse processo é chamado validação cruzada.
Ajuste do modelo e realização de predições
Uma vez que os dados estão preparados, a regressão logística é realizada. O programa vai utilizar os dados do conjunto “treinamento” para aprender quais variáveis são preditoras do churn. Depois, outros testes estatísticos são utilizados para avaliar se essas predições correspondem aos dados do grupo “teste”. Um desses testes é a matriz de confusão, que pode ser gerada para identificar os acertos e erros do modelo.
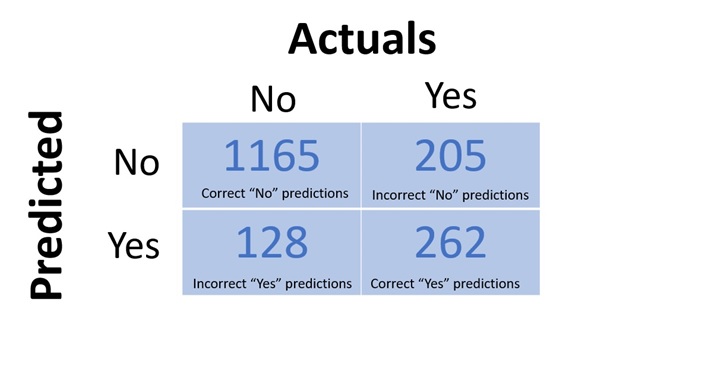
Impacto nos negócios
Como utilizar esses dados para aumentar a taxa de retenção de consumidores e diminuir custos? Vamos supor que o custo de aquisição de um cliente na indústria da telecomunicação é aproximadamente $300. Logo, se o programa previr que um cliente não irá embora, mas ele for (resultado falso negativo), será necessário gastar $300 para adquirir um substituto para esse cliente.
Vamos supor também que é cinco vezes mais caro adquirir um novo cliente do que manter um existente. Assim, se o programa previr que um cliente irá embora, será necessário gastar $60 para tentar manter esse cliente. Algumas vezes essa previsão de churn será correta (verdadeiro positivo) e algumas vezes será incorreta (falso positivo). Em ambos os casos, serão gastos $60 para reter o cliente.
Finalmente, há o cenário no qual o programa corretamente prevê que o cliente não irá embora (verdadeiro negativo). Nesse caso, nenhum dinheiro será gasto. São clientes satisfeitos que foram corretamente identificados.
Então, vamos recapitular os custos:
Falso negativo (previsão de que não ocorre churn, mas ocorre): $300
Verdadeiro positivo (previsão de que ocorre churn e, de fato, ocorre): $60
Falso positivo (previsão de que ocorre churn, mas não ocorre): $60
Verdadeiro negativo (previsão de que não ocorre churn e, de fato, não ocorre): $0
Se multiplicarmos o número de cada tipo de previsão (FN, VP, FP e VN) pelo custo de cada um e somarmos todos os custos, podemos calcular o custo total associado ao modelo. Eis a equação:
Custo total = FN($300) + VP($60) + FP($60) + VN($0)
Em seguida, por meio da matriz de confusão, é calculado o custo médio de cada cliente. Então, o modelo é ajustado até que o custo de cada cliente chegue a um valor mínimo. Ou seja, o modelo é refinado até que o número de erros de previsão seja o menor possível, o que diminuirá custos e otimizará as taxas de retenção.
No case abordado, o custo por consumidor foi reduzido de $48 para $40. Se a empresa tivesse uma base de 500 mil consumidores, isso produziria uma economia anual de $4 milhões. Um impacto significativo nos negócios, não?


