

Conheça as aplicações de Ciência de Dados para a área de modelagem de risco e as suas vantagens em comparação aos sistemas tradicionais
Existe um elemento de risco quando as instituições financeiras emprestam dinheiro a clientes. Portanto, é de interesse delas reduzir o risco e emprestar dinheiro apenas para clientes que têm certeza de que irão pagá-las.
O aprendizado de máquina contribui significativamente para os aplicativos de modelagem de risco de crédito. O custo do risco é um dos maiores componentes da estrutura de custos dessas organizações em geral, como bancos ou fintechs. Assim, mesmo uma pequena melhoria nesta modelagem pode se traduzir em grandes economias.
Além disso há falhas histórias nas abordagens tradicionais.
Os sistemas convencionais são rígidos, baseados em regras, o que significa que se o indivíduo não tiver um histórico perfeito de empréstimos anteriores, dificilmente obterá um novo empréstimo.
Mas como uma pessoa sem banco pode obter seu primeiro empréstimo? E como um indivíduo em busca de dinheiro para abrir uma empresa pode começar a ganhar para pagar o empréstimo? Essas complexidades não estão incluídas na abordagem clássica da modelagem de crédito, permitindo que apenas a população bancária com um bom histórico de liquidação de empréstimos obtenha mais empréstimos no futuro.
As falhas mais significativas que impedem os sistemas de modelagem de crédito tradicionais de fornecer avaliações precisas de qualidade de crédito são análises baseada apenas em dados históricos, além de vieses e percepções humanas corrompendo os parâmetros de pontuação de risco, a capacidade de avaliar apenas relações lineares.
Hoje, o reconhecimento de novos direcionadores de risco é essencial na pontuação sensível e responsiva do risco de crédito. Um critério vital de sustentabilidade empresarial para credores comerciais é o que a ciência de dados pode capturar, enquanto humanos e sistemas baseados em scorecards não podem. Todos esses aspectos podem ser incluídos em um sistema de aprendizado de máquina para receber avaliações abrangentes e realistas dos perfis dos clientes, levando a uma diferenciação mais inteligente do cliente e ao cálculo do risco de crédito.
Abaixo conseguimos notar a diferença com a utilização de Machine Learning.
O processo padrão
Os pedidos de empréstimo são geralmente avaliados por meio de um modelo de pontuação de crédito, que na maioria das vezes se baseia em uma regressão logística (LR). Ele é treinado em dados históricos, como histórico de crédito. O modelo avalia a importância de cada atributo fornecido e os traduz em uma previsão.
A principal limitação desse modelo é que ele pode levar em consideração apenas dependências lineares entre as variáveis de entrada e a variável prevista. Por outro lado, é essa mesma propriedade que torna a regressão logística tão interpretável.
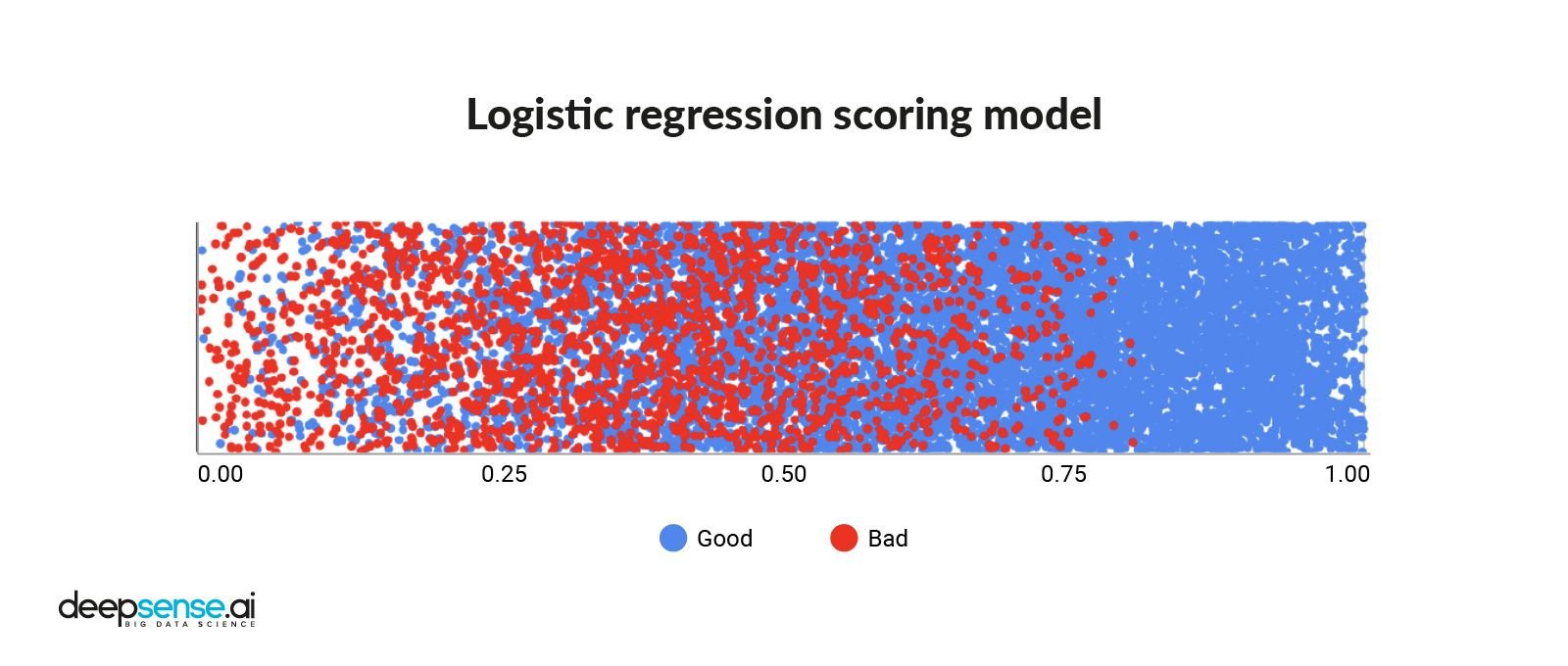
Pontuação de crédito a partir de um modelo de regressão logística. Extraído de Deep Sense.ai
O processo de Machine Learning
O aprendizado de máquina permite a utilização de técnicas de modelagem mais avançadas, como árvores de decisão e redes neurais. Isso introduz não linearidades no modelo e permite detectar dependências mais complexas entre os atributos.
No exemplo a seguir, há um modelo XGBoost alimentado com recursos selecionados com o uso de um método chamado importância da permutação.
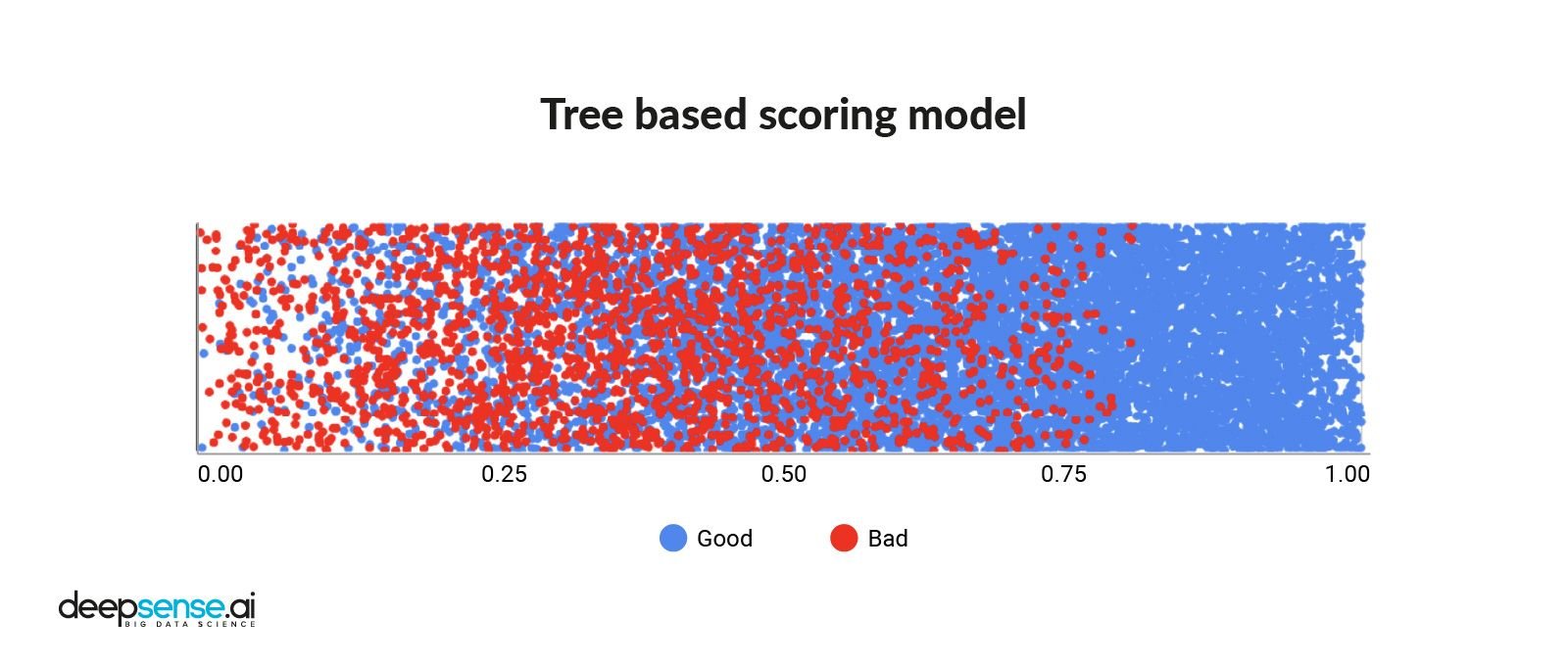
Pontuação de crédito do modelo baseado em árvore. Extraído de Deep Sense.ai
No entanto, os modelos de ML geralmente são bastante sofisticados e se tornam difíceis de interpretar. Como a falta de interpretabilidade seria um problema sério em um campo altamente regulamentado como a avaliação de risco de crédito, é interessante combinar o XGBoost baseado em ML e a regressão logística.
Usando os dois mecanismos de pontuação para avaliar pedidos de empréstimo, há uma correlação clara entre as duas abordagens de avaliação, uma pontuação alta em um modelo provavelmente significaria uma pontuação alta no outro:
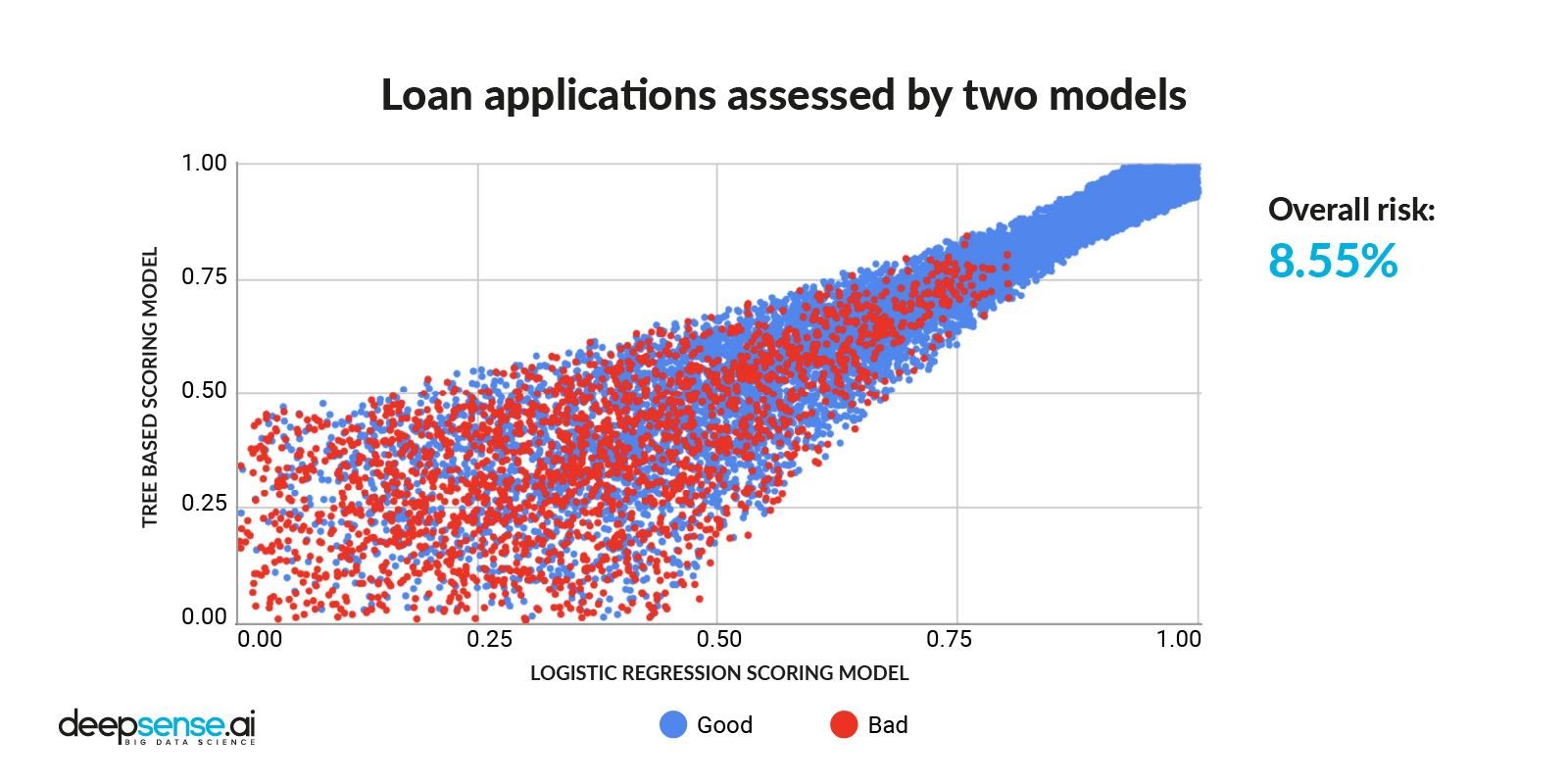
Pedidos de empréstimo avaliados por 2 modelos
Na abordagem original, a regressão logística foi usada para avaliar as aplicações. O nível de aceitação foi definido em torno de 60% e o risco resultou em 1%.
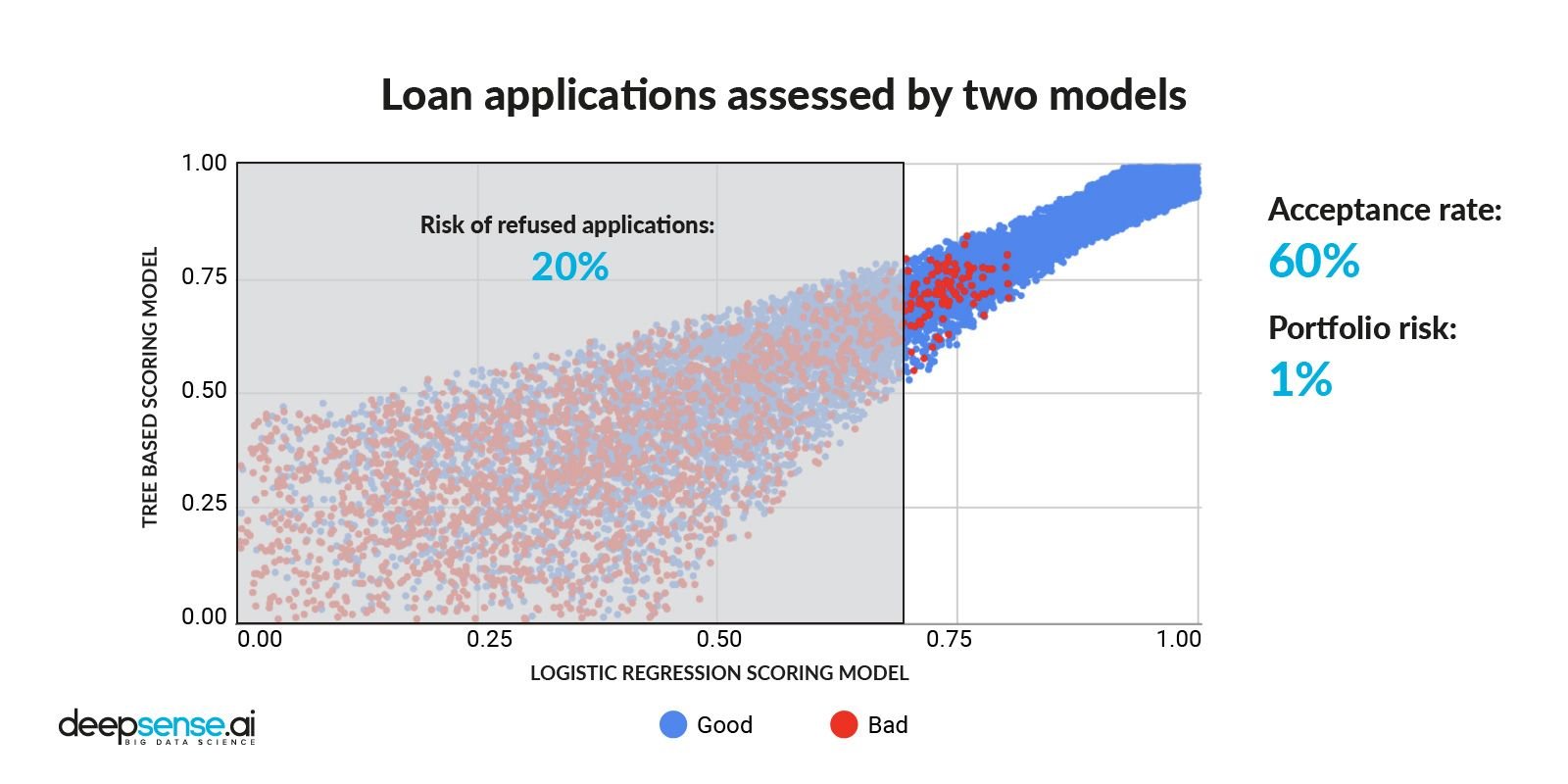
Divisão inicial do pedido de crédito (aceitação ao risco da carteira)
Se diminuir o limite em alguns pontos, o nível de aceitação atinge 70%, enquanto o risco salta para 1,5%
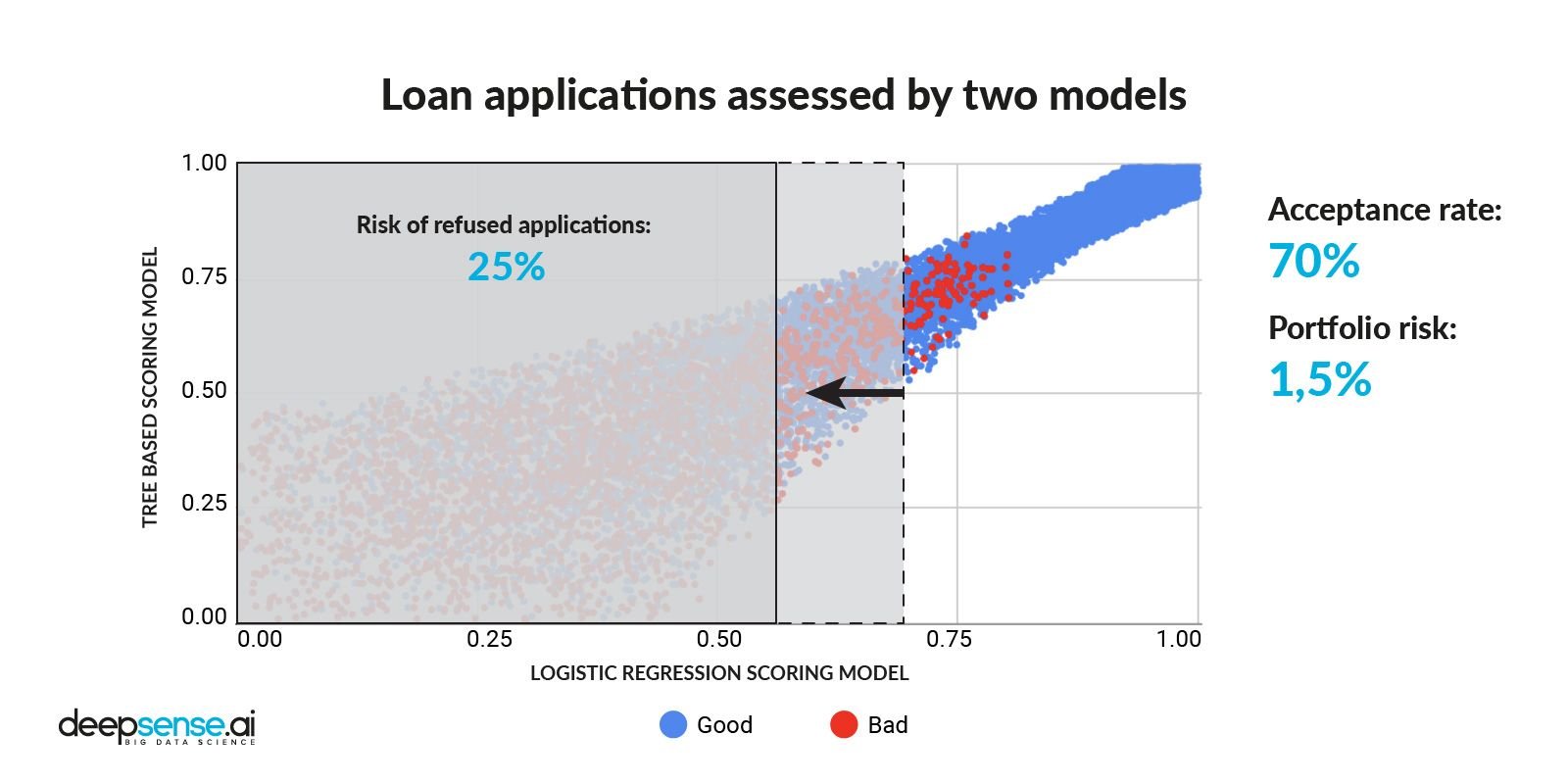
Divisão de aplicativos de crédito após reduzir o limite
Em seguida, aplicando um limite para um modelo de ML, é possível obter uma porcentagem de aceitação para o nível original (60%), enquanto risco é reduzido para 0,75%, que é 25% menor do que o nível de risco resultante apenas da abordagem tradicional.
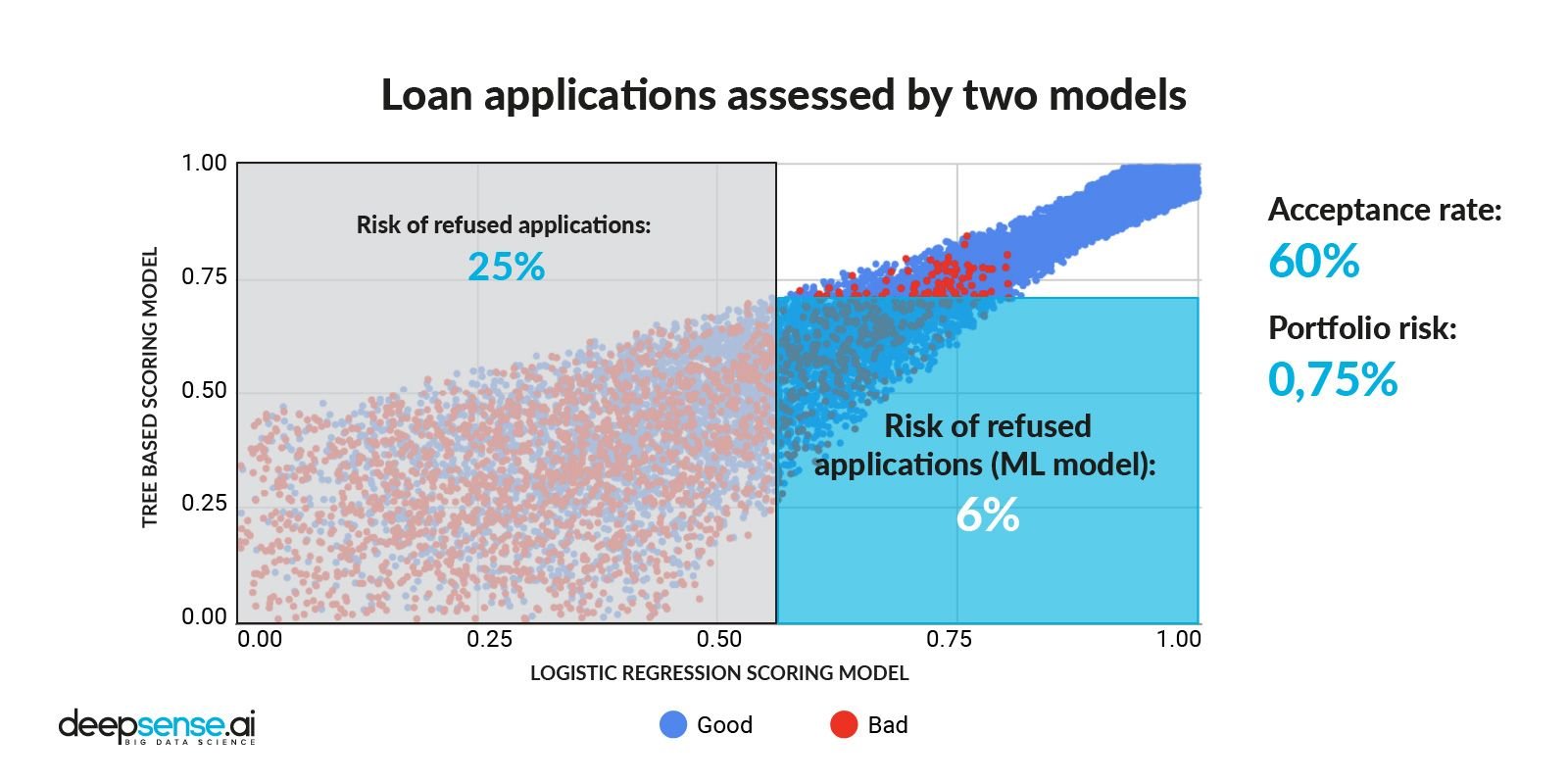
Divisão de aplicativos de crédito após a aplicação do aprendizado de máquina
O aprendizado de máquina costuma ser visto como difícil de aplicar no setor bancário devido à grande quantidade de regulamentação que o setor enfrenta, mas os ganhos podem valer bastante o esforço. Graças a abordagens inovadoras como esta, é possível aumentar a sustentabilidade do setor de crédito e torná-lo ainda mais acessível aos clientes bancários.
Os algoritmos de pontuação de crédito tradicionais funcionam linearmente, analisando dados históricos para produzir estimativas da qualidade de crédito futura. Os sistemas de aprendizagem automática de autoaprendizagem, por outro lado, usam dados históricos e atuais para melhorar sua capacidade de previsão. Isso ajudar a estabelecer conexões entre variáveis fragmentadas, proporcionando uma visão muito mais aprofundada do perfil do mutuário. Esses recursos contribuem para o potencial preditivo cada vez maior de algoritmos de aprendizado de máquina e uma melhor análise de dados não estruturados.
Embora muitos usuários considerem os sistemas de aprendizado de máquina muito caros para implementar, na realidade, esses modelos são mais econômicos a longo prazo. Uma vez que são construídos, podem ser usados repetidamente para todos os tipos de casos de uso de crédito. A maioria dos provedores de soluções de pontuação de crédito baseadas em scorecard cobram dos usuários com base no princípio por usuário. Ao mesmo tempo, os modelos de aprendizado de máquina representam todo um sistema personalizável e de aprendizado contínuo, capaz de atender a todas as necessidades de pontuação de crédito e perfil de clientes. Por exemplo, modelos de ML podem fornecer sistemas de pontuação de crédito capazes de fornecer previsão de elegibilidade precisa e classificação inteligente de mutuário para minimizar o número de empréstimos potencialmente “ruins”. Isso melhora a relação custo-benefício da solução de ML.
Uma solução de ciência de dados eficaz pode não apenas tornar o crédito acessível para muitos clientes, mas também pode ajudar as empresas financeiras a alcançar muitos clientes em potencial.


