É preciso ter cuidado ao interpretar modelos preditivos de aprendizado de máquina em busca de percepções causais. Aquilo que parece, nem sempre é.
Modelos de aprendizagem de máquina preditivos podem se tornar ainda mais poderosos quando ligados a ferramentas de interpretação, que identificam as principais relações entre os recursos de entrada e o resultado previsto. Isso é muito útil para explicar o que o modelo está fazendo e diagnosticar problemas potenciais. Mas, vamos ver que a utilização de modelos preditivos para mexer alavancas de negócios esconde armadilhas que podem levar a suposições e tomadas de decisão erradas.
O motivo está relacionado à diferença entre correlação e causalidade. É o que explicam engenheiros e cientistas de dados da Microsoft em artigo do Towards Data Science. O fato é que, tornar as correlações dos modelos transparentes não as tornam causais.
Um exemplo de retenção de clientes
Vamos imaginar a tarefa de construir um modelo que prevê se um cliente renovará sua assinatura de uma plataforma online. Após um pouco de pesquisa, entendemos que existem oito recursos importantes para prever sua rotatividade:
-
desconto;
-
gastos com anúncios;
-
utilização mensal da plataforma;
-
última atualização;
-
bugs relatados pelo cliente;
-
interações do cliente com a empresa;
-
ligações de vendas;
-
e a economia em geral.
Em seguida, usamos esses recursos para treinar um modelo preditivo de Machine Learning como XGBoost para prever se um cliente renovará sua assinatura quando ela expirar:
X, y = user_retention_dataset ()
model = fit_xgboost (X, y)
Assim que tivermos nosso modelo de retenção de clientes em mãos, podemos começar a explorar o que ele aprendeu com uma ferramenta de interpretabilidade como o SHAP. Começamos traçando a importância global de cada recurso no modelo:
xplanador = shap.Explainer (modelo)
shap_values = explainer (X)clust = shap.utils.hclust (X, y, linkage = “único”)
shap.plots.bar (shap_values, clustering = clust, clustering_cutoff = 1)

O gráfico mostra que o desconto oferecido, o gasto com anúncios e o número de bugs relatados são os três principais fatores que impulsionam a previsão do modelo de retenção de clientes. Em uma primeira impressão, parece um resultado que faz sentido e que pode ser trabalhado pela equipe.
Porém, quando olhamos mais de perto e observamos como a alteração do valor de cada recurso afeta a previsão do modelo, encontramos alguns padrões não intuitivos:

Os gráficos de dispersão mostram como a alteração do valor de um recurso impacta a previsão do modelo das probabilidades de renovação. Se os pontos azuis seguirem um padrão crescente, isso significa que quanto maior o recurso, maior é a probabilidade de renovação prevista do modelo.
Temos aqui algumas descobertas. Primeiro, que os usuários que relatam mais bugs têm maior probabilidade de renovar. E os usuários com descontos maiores têm menos probabilidade de renovar.
Pode parecer um tanto estranho, mas aqui entram percepções das áreas de negócio que ajudam a esclarecer o cenário. Eles explicam que os usuários que relatam bugs são mais propensos a renovar suas assinaturas porque utilizam mais o produto e também o valorizam. Por outro lado, a força de vendas tende a dar grandes descontos aos clientes que eles acreditam ter menos probabilidade de se interessar pelo produto – e justamente esses clientes apresentam maior rotatividade. Eles estão ali mais por preço, não tanto pelo valor que o produto agrega a ele.
Nesse caso, se o objetivo é prever a retenção de clientes, ele foi alcançado, e isso é muito útil para projetos como estimar receitas futuras para planejamento financeiro. É um exemplo de uma classe de tarefas chamadas tarefas de previsão, onde o objetivo é prever um resultado Y (por exemplo, renovações) dado um conjunto de recursos X.
Mas vamos supor que outra equipe utilize esse modelo de previsão com o novo objetivo de determinar quais ações a empresa pode realizar para reter mais clientes. Nesse caso, não é mais suficiente identificar uma correlação estável entre as variáveis; esta equipe quer saber se mexer no recurso X vai causar uma mudança no resultado Y. Mas não faz sentido nenhum introduzir novos bugs no sistema para aumentar as renovações de clientes.
Este é um exemplo de uma classe chamada de tarefas causais. Em uma tarefa causal, queremos saber como mudar um aspecto do mundo X (por exemplo, bugs relatados) afeta um resultado Y (renovações). Aqui é fundamental saber se a mudança X causa um aumento em Y ou se a relação nos dados é meramente correlacional.
Os desafios de estimar os efeitos causais
Este gráfico causal ilustra por que as relações preditivas captadas pelo modelo de retenção de clientes diferem das relações causais de interesse da equipe que deseja planejar intervenções para aumentar a retenção.

Os balões sólidos representam recursos que observamos, enquanto balões tracejados representam recursos ocultos que não medimos.
Existem muitas relações neste gráfico, mas a primeira preocupação importante é que alguns dos recursos que podemos medir são influenciados por características confusas não medidas como a necessidade do produto e os bugs enfrentados. Por exemplo, os usuários que relatam mais bugs estão encontrando mais bugs porque usam mais o produto e também são mais propensos a relatar esses bugs porque precisam mais do produto. A necessidade do produto tem seu próprio efeito causal direto na renovação. Essas são relações de moderação e mediação entre diferentes variáveis, que podem tanto sustentar quanto fortalecer a relação entre elas.
Como não podemos medir diretamente a necessidade do produto – uma variável mediadora nesse caso – a correlação que acabamos capturando em modelos preditivos entre os bugs relatados e a renovação combina um pequeno efeito direto negativo dos bugs enfrentados e um grande efeito de confusão positivo da necessidade do produto.
A figura abaixo representa os valores em relação ao verdadeiro efeito causal de cada recurso (conhecido neste exemplo desde que geramos os dados).

O modelo preditivo captura um efeito geral positivo dos bugs relatados na retenção, embora o efeito causal de relatar um bug seja zero e o efeito de encontrar um bug seja negativo.
Vemos um problema semelhante com descontos, que também são impulsionados pela necessidade não observada do cliente para o produto. Nosso modelo preditivo encontra uma relação negativa entre descontos e retenção, mediada pela variável não observada de Necessidade do Produto (embora haja realmente um pequeno efeito causal positivo de descontos na renovação). Isso significa que, se dois clientes estão com um nível semelhante de Necessidade de Produto, o cliente com o desconto maior terá maior probabilidade de renovar.
Quando os modelos preditivos podem responder a questões causais
Observe que nosso modelo preditivo faz um bom trabalho ao capturar o efeito causal real do recurso Economia (uma economia melhor tem um efeito positivo na retenção). Então, quando os modelos preditivos vão capturar os verdadeiros efeitos causais?
Nesta simulação, o ingrediente importante que permitiu ao modelo XGBoost obter uma boa estimativa do efeito causal para Economia é o forte componente independente da variável. Seu poder preditivo para retenção não é fortemente redundante com quaisquer outros recursos medidos ou com quaisquer fatores de confusão não medidos.
Consequentemente, não está sujeito a distorções de fatores de confusão não medidos ou redundância de recursos.

A economia é independente de outros recursos medidos.
Podemos ver que a Economia é independente de todos os outros recursos medidos, por isso não sofre de confusão observada. Mas para confiar que o efeito Economia é causal, também precisamos verificar se há confusão não observada.
Quando os modelos preditivos não podem estabelecer relacões causais, mas os métodos de inferência podem ajudar
Na maioria dos conjuntos de dados, os recursos não são independentes e infundados, portanto, os modelos preditivos padrão não aprenderão os verdadeiros efeitos causais. Mas, às vezes é possível consertar ou pelo menos minimizar esse problema usando as ferramentas de inferência causal observacional.
Confusão observada
O primeiro cenário em que a inferência causal pode ajudar é a confusão observada. Uma variável é “confundida” quando há outra que afeta causalmente tanto sua característica original quanto o resultado que estamos tentando prever. Se pudermos medir essa outra característica, ela é chamada de fator de confusão observado.
Um exemplo disso em nosso cenário é o recurso Ad Spend. Mesmo que o Ad Spend (gasto com anúncios) não tenha efeito causal direto na retenção, ele está correlacionado com as variáveis de Last Upgrade (última atualização) e Monthly Usage (uso mensal), que impulsionam a retenção. É um antecedente que pode ser controlado e gerenciado na prática.

Os gastos com anúncios não estabelecem relação de causalidade com retenção.
Nosso modelo preditivo identifica o gasto com anúncios como um dos melhores preditores de retenção porque captura muitos dos “verdadeiros” impulsionadores, com relações causais mais diretas. Esta propriedade do modelo é muito útil para gerar boas previsões de retenção futura, mas não é boa para entender quais variáveis devemos manipular se quisermos aumentar a diretamente retenção, mas sim seus antecedentes.
Isso destaca a importância de combinar as ferramentas de modelagem certas para cada pergunta. Ao contrário do exemplo de relatório de bug, não há nada intuitivamente errado com a conclusão de que aumentar os gastos com anúncios aumenta a retenção. Sem a devida atenção ao que nosso modelo preditivo está ou não medindo, podemos nos enganar sobre quais de fato são as alavancas que devemos puxar e o que elas efetivamente podem fazer pelos nossos negócios.
Inferência Causal Observacional
A boa notícia para os gastos com anúncios é que podemos medir todos os recursos que podem confundi-lo (as variáveis com setas em gasto com publicidade em nosso gráfico acima). Portanto, este é um exemplo de confusão observada. É possível separar os padrões de correlação usando apenas os dados já coletados utilizando ferramentas que permitem especificar quais variáveis podem confundir o gasto com anúncios e, em seguida, ajustar para esses recursos, para obter uma estimativa do efeito causal do gasto com publicidade na renovação do produto.
Uma delas pode ser o aprendizado de máquina duplo, que funciona basicamente da seguinte maneira:
-
Treine um modelo para prever um recurso de interesse (ou seja, Ad Spend) usando um conjunto de possíveis fatores de confusão (ou seja, quaisquer recursos não causados por Ad Spend);
-
Treine um modelo para prever o resultado (ou seja, Renovação) usando o mesmo conjunto de possíveis fatores de confusão;
-
Treine um modelo para prever a variação residual do resultado (a variação restante após subtrair nossa previsão) usando a variação residual da característica causal de interesse.
Rodando isso, o processo retorna um valor P, que nos diz que se esse tratamento tem um efeito causal diferente de zero e funciona em nosso cenário, identificando corretamente que não há evidência de um efeito causal de gastos com publicidade na renovação (valor P = 0,85):
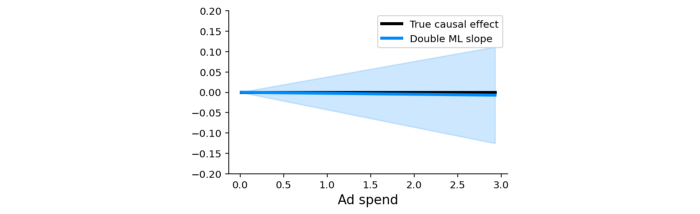
Com isso, podemos ver que o uso mensal e a última atualização são os dois fatores de confusão diretos que precisamos controlar.
Quando nem os modelos preditivos nem os métodos não fundamentados podem responder a questões causais
O ML duplo (ou qualquer outro método de inferência causal que pressupõe falta de fundamento) só funciona quando você pode medir e identificar todos os possíveis fatores de confusão da variável para o qual deseja estimar os efeitos causais. Se você não pode medir todos os fatores de confusão, então você está no cenário mais difícil possível: confusão não observada.

Os recursos Desconto e Bugs relatados sofrem de confusão não observada porque nem todas as variáveis importantes (por exemplo, Necessidade do produto e Bugs encontrados) são medidas nos dados. Embora ambos os recursos sejam relativamente independentes de todos os outros recursos do modelo, existem fatores importantes que não são medidos. Nesse caso, tanto os modelos preditivos quanto os modelos causais que requerem a observação de confundidores, como o ML duplo, falharão.
Nessas situações, a única maneira de identificar os efeitos causais é criar ou explorar alguma randomização que quebre a correlação entre as características de interesse e os fatores de confusão não medidos.
Podemos dizer, por fim, que modelos preditivos de machine learning são ótimos para resolver problemas de previsão. No entanto, são modelos não inerentemente causais e enfrentam dificuldades de oferecer respostas definitivas. As suposições que fazemos ao interpretar um modelo preditivo normal como causal são frequentemente irrealistas e precisam ser examinados mais de perto, sobretudo com fundamentação teórica para não sermos levados ao engano por variáveis que não fazem sentido e vão provocar erros de estratégia e alocação de recursos.


