
Apresentamos uma análise do que aconteceu em 2020 de forma global no ecossistema de Dados e as principais tendências de tecnologia da área a partir do estudo de uma Venture Capital americana.
2020 está sendo um ano único, como nenhum outro na história recente. Neste contexto dos negócios e sua reinvenção, transformação e adaptação, o ecossistema de Dados ao redor do mundo é um dos que mais se sobressai, mostrando seu poder de fornecer recursos competentes em meio a uma crise mundial.
Nas palavras do indiano Satya Nadella, CEO da Microsoft, “vimos dois anos de transformação digital em dois meses […] em um mundo onde tudo é remoto”. Além da computação em nuvem, tecnologias específicas de dados estão no centro dessa mudança, como infraestrutura de dados, aprendizado de máquina, inteligência artificial e aplicações orientadas a dados.
Um dos mais emblemáticos casos dessa aceleração foi a Snowflake, um provedor de armazenamento de dados em nuvem dos EUA, que abriu capital na Nasdaq em setembro e alcançou o maior IPO de uma empresa de software na história da bolsa de valores, com seu valor de mercado saltando para US$ 69 bilhões. Embora existam muitos fatores econômicos a considerar, é seguro fizer que o mercado financeiro está recompensando uma realidade cada vez mais clara: para ter sucesso, toda empresa moderna precisará ser não apenas uma empresa de software, mas também uma empresa de dados.
Abaixo, apresentamos uma análise do que aconteceu em 2020 de forma global e as principais tendências de tecnologia de dados a partir do estudo da Venture Capital americana First Mark.
Principais tendências em infraestrutura de dados
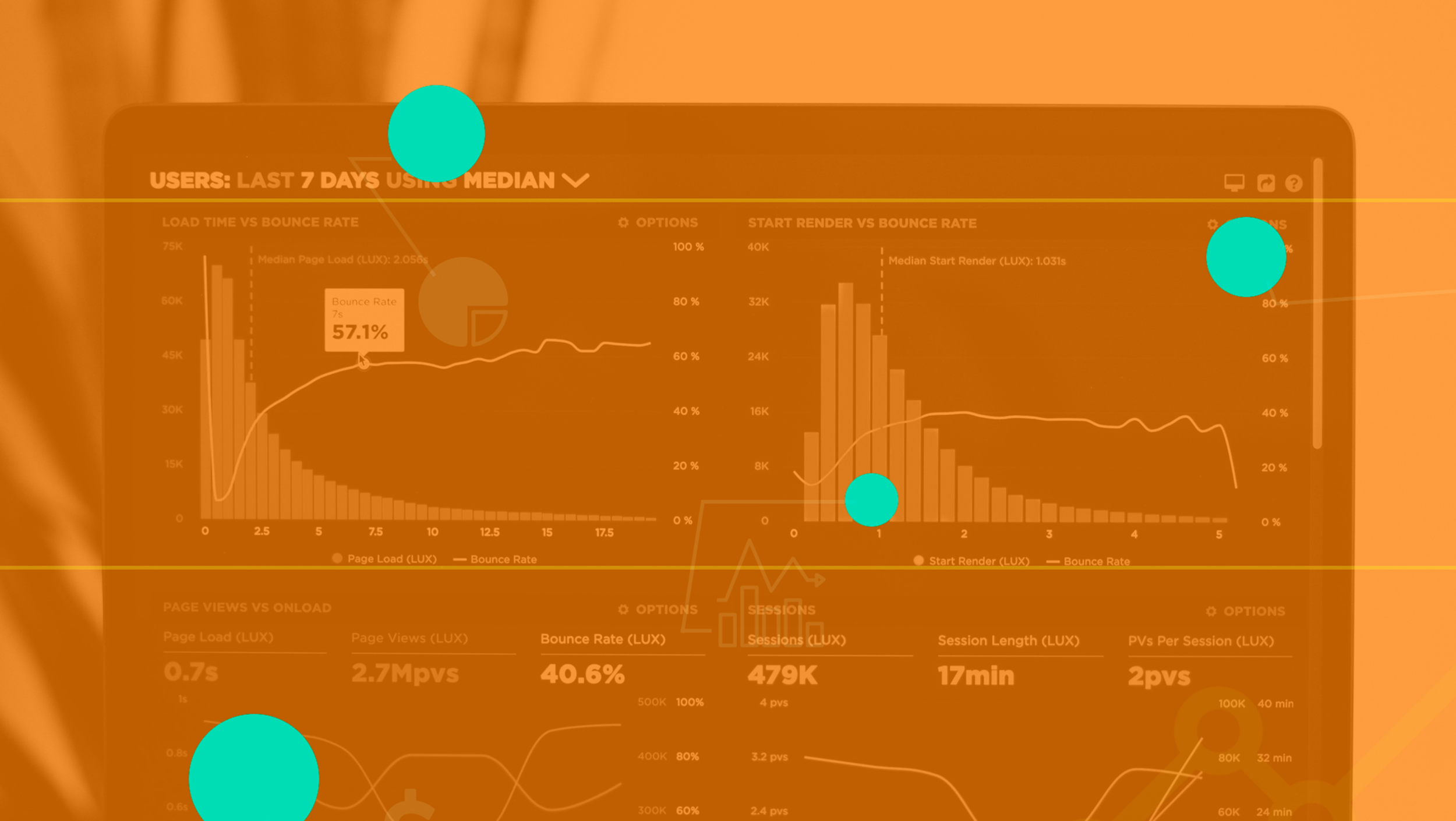
À medida que as empresas começam a colher os benefícios das iniciativas de dados querem mais: podemos processar mais dados, mais rápido e mais barato? Colocar mais modelos de ML em produção? Fazer mais em tempo real? Isso eleva o nível da infraestrutura de dados e oferece muito espaço para inovação.
O stack de dados se torna convencional
O stack de dados é compreendido como um conjunto de ferramentas e tecnologias que permitem análises, principalmente para dados transacionais. O conceito surgiu em 2012, com o lançamento do Redshift, o data warehouse em nuvem da Amazon. Nos últimos dois anos, sua popularidade cresceu e explodiu em 2020, assim como todo um ecossistema de ferramentas e empresas ao seu redor.
A ideia deste conceito é construir um pipeline onde primeiro se extrai dados de várias fontes diferentes, armazena-os em um data warehouse centralizado, que é escalável e elástico e, em seguida, analisa e visualiza.
Existem inúmeros tipos de pipelines de dados, mas um padrão de um stack está ilustrado na figura abaixo, pelo menos para dados transacionais:
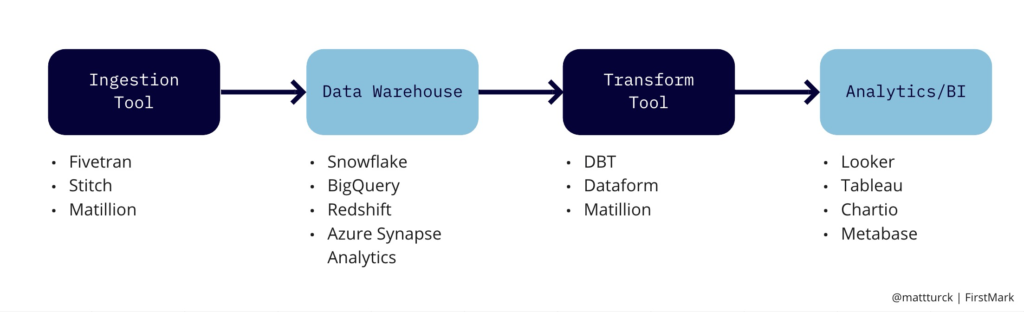
ETL vs ELT
Data warehouses, ou armazéns de dados, costumavam ser caros e não-elásticos. Então era preciso extrair os dados das fontes, transformar para o formato desejado e então carregue na nuvem. Era o processo de Extract, Transform, Load – ETL – ou Extrair, Transformar, Carregar.
Atualmente é possível despejar tudo nos data warehouses sem se preocupar com escala ou formato. O processe virou Extract, Load and Transform – ELT – ou Extrair, Carregar e Transformar. A área evolui rapidamente, com diversos players e ferramentas ganhando espaço e fomentando discussões sobre segurança e governança desses dados em nuvem.
Automação de Engenharia de Dados
ETL é uma área altamente técnica e, em grande parte, deu origem à engenharia de dados como uma disciplina separada. No entanto, como os data warehouses em nuvem possibilitam “apenas” extrair e carregar os dados, sem ter que transformá-los tanto, há uma oportunidade de automatizar muito mais a tarefa de engenharia.
Assim, estão surgindo diversas empresas focadas nessa automação da engenharia de dados, como uma grande biblioteca de APIs pré-construídas para extrair dados de fontes populares e carregá-los nos data warehouses. Tudo de maneira automatizada, gerenciada e sem manutenção.
Ascensão do Analista de Dados
Os analistas de dados estão assumindo um papel de maior protagonismo no gerenciamento e análise de dados. Tradicionalmente, os analistas de dados lidariam apenas com a última parte do pipeline de dados – análise, inteligência de negócios, visualização. Agora, como os data warehouses em nuvem são grandes bancos de dados relacionais, os analistas de dados podem ir muito mais fundo no território que era tradicionalmente tratado por engenheiros de dados e, por exemplo, lidar com transformações, aproveitando suas habilidades em SQL (DBT, Dataform e outros sendo estruturas baseadas em SQL).
Para as empresas, pode ser uma boa notícia, pois os engenheiros de dados continuam sendo raros e caros e, em relação a eles, os analistas de dados tem um treinamento muito mais rápido e fácil, além de uma onda de novas empresas criando ferramentas modernas centradas no analista para extrair insights e inteligência dos dados.
Data lakes e data warehouses se fundindo
Outra tendência de simplificação do stack de dados é a unificação de data lakes e data warehouses. Alguns chamam essa tendência de “data lakehouse”, outros chamam de “Unified Analytics Warehouse”.
Historicamente, existem data lakes de um lado – grandes repositórios de dados brutos, em uma variedade de formatos, que são de baixo custo, muito escalonáveis, mas não suportam transações, qualidade de dados, etc. – e data warehouses do outro lado – muito mais estruturados, com recursos transacionais e de governança de dados.
O resultado é que, em muitas empresas, existem um data lake e vários data warehouses, com muitos pipelines de dados paralelos. As empresas em nuvem tentam fundir os dois lados para gerar uma experiência unificada para todos os tipos de análise de dados, incluindo BI e aprendizado de máquina. Por exemplo, o Snowflake se apresenta como um complemento ou substituto potencial para um data lake. O Synapse, data warehouse em nuvem da Microsoft, tem recursos integrados de data lake. O Databricks fez um grande esforço para se posicionar como um lakehouse completo.
A complexidade sempre está presente
Essas tendências apontam para stacks de dados mais simples e acessíveis às empresas, mas a complexidade por trás de tudo também aumenta. O volume geral de dados fluindo continua crescendo explosivamente. O número de fontes de dados também, com cada vez mais ferramentas SaaS. Geralmente não há um, mas muitos pipelines de dados operando em paralelo na empresa, além da maioria dos serviços estar focada no mundo dos dados transacionais e BI, mas muitos pipelines de aprendizado de máquina são totalmente diferentes.
Há também uma necessidade crescente de tecnologias de streaming em tempo real. Assim, as ferramentas mais complexas continuam com bastante espaço para crescer, assim como a demanda por engenheiros de dados que possam implantar essas tecnologias em escala.
Toda essa complexidade gera necessidade de soluções DataOps, que é uma área emergente também porque há uma necessidade relacionada a soluções que garantam a qualidade de dados. No geral, a governança de dados continua a ser um requisito fundamental para as empresas.


