
Este é um guia com classificações fundamentais relativas a dados, como fontes, estrutura, características, granularidade e variáveis. Um material para consultar a qualquer momento.
Sem pensar muito, quando as pessoas no geral falam em “dados”, dá a impressão de que é algo ali disponível, pronto para usar. Mas a verdade é que, fazendo um paralelo com o processo industrial, dados normalmente chegam de uma maneira bastante caótica, bruta e com muitas e muitas categorias, tipos, classificação, fontes, etc.
Ter domínio dessa pluralidade faz toda a diferença para termos um melhor diálogo com áreas técnicas e também conseguirmos entender o que é possível de se alcançar com determinados dados e a que custo de trabalho.
Por conta de tudo isso, preparamos um guia com algumas classificações fundamentais em relação a dados, para alinhar um conhecimento básico e servir como fonte de consulta geral.
Fonte
A primeira classificação importante é em relação à fonte de aquisição dos dados, ou seja, de onde eu posso “extrair a matéria-prima”, para seguir na metáfora industrial.
De maneira geral, os dados sempre foram primários ou secundários, ou seja, próprios ou de outros agentes. Gerados internamente ou externamente. Porém, dados têm virado cada vez mais objeto de comercialização, o que faz com que precisemos destrinchar um pouco mais a classificação:
Dados primários
Dados obtidos de geração própria, da própria empresa ou da própria pesquisa. São dados captados no CRM, nas redes sociais, no site da própria empresa, por exemplo. Tudo aquilo que é de domínio próprio da organização.
Dados secundários
São dados não próprios, de uma segunda fonte externa, mas que tem uma característica importante do dado não ser público. O dado que se obtém em uma second party não pode ser adquirido livremente por qualquer empresa. É o caso de parcerias de troca de dados entre empresas, que muitas vezes estão em setores complementares, mas não concorrentes.
Dados terciários
São também dados externos, não próprios, mas esses sim públicos. Qualquer outra empresa pode ter acesso, de forma paga ou gratuita. Hoje muitas empresas fazem coleta, armazenamento e enriquecimento de dados públicos para serem comercializados livremente no mercado.

Estrutura
Outra questão importante é a forma como um dado se estrutura (ou não se estrutura). Podemos dar status de “dado” a praticamente qualquer coisa que tem o poder de gerar uma informação registrada. Porém, nesse aspecto estrutural, eles se dividem em pelo menos três formas:
Dados não-estruturados
São os dados estruturalmente mais brutos, capturados sem classificação ou esquema formal. São dados como posts em redes sociais, imagens, vídeos, e-mails, etc. Apesar de serem, sem dúvida, os dados mais abundantes que existem, eles requerem um grande trabalho – estratégico e operacional – para poderem ser utilizados de maneira útil por uma organização.
Dados semi-estruturados
São dados igualmente sem uma organização esquemática, mas aqui já classificados de alguma forma. Isso significa que há como saber como os dados estão separados, mas não há como trabalhar neles por falta de um esquema formal. Um dos melhores exemplos é o back-end de uma página de texto publicada na web. Ela tem uma codificação (na linguagem que estiver sendo utilizada) que é possível identificar a que classe pertence qual elemento. Mas não é possível fazer qualquer tipo de análise, porque não há um esquema que permita quantificações.
Dados estruturados
São aqueles que têm uma classificação e uma lógica formal na maneira como são esquematizados. Aqui estamos falando de dados em um banco, com linhas, colunas, como todo mundo conhece. Esses são os dados que poderão ser utilizados por estatísticos e cientistas de dados para gerar modelos e algoritmos.
Então, no fundo, tanto dados desestruturados quanto desestruturados precisam passar por algum processo de estruturação para serem usados

Imagens de aula da Sandbox Escola de Estratégia, no curso Data LIVE.
Característica
Além de estrutura, dados também têm suas características próprias. Cada um deles tem uma natureza funcional distinta e essa classificação nos ajuda inclusive a planejar uma coleta e armazenamento mais adequados.
As características iriam longe porque existem muitos e muitos tipos de dados que poderiam se encaixar sob essa perspectiva funcionalista. Porém, vamos nos concentrar aqui em quatro principais, que cobrem os aspectos mais importantes.
Dados transacionais
São dados que estão em constante mudança ou atualização e registram eventos que ocorrem em uma periodicidade constante, definida ou não. Apesar do nome levar imediatamente para questões como compras, vendas, cancelamentos etc., não é apenas isso que compõe os dados transacionais. Na área de RH, as contratações de novos funcionários são um tipo de dado transacional. Em termos de logística, dados de estoque ou de entregas também são transacionais.
Dados master
São dados que caracterizam, de alguma forma, o perfil dos agentes das transações. Informações de sexo, renda, escolaridade de um cliente, por exemplo. Podem descrever as características de determinado produto vendido em um e-commerce. Um sapato, por exemplo: sua cor, tamanho, modelo. Os dados máster dão suporte analíticos aos dados transacionais.
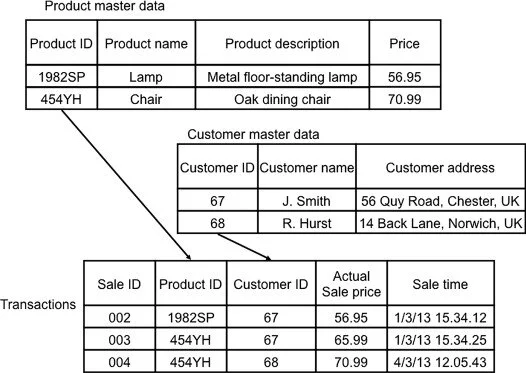
Dados de referência
São um tipo mais específico de máster data relacionado a classificações um pouco mais padronizadas, que raramente se alteram e podem descrever dados de um caso particular de maneira praticamente universal. Aqui estamos falando de classificações como ISOs, CEP, medidas de tempo, comprimento, peso, códigos telefônicos de países ou DDD. São todos dados com um padrão de referência bastante difundido, que pode ser cruzado inclusive com outros bancos de dados para enriquecimento de informações.
Metadados
São aqueles dados que fornecem informações sobre outros dados. Um exemplo fácil do dia a dia está no nosso computador. Quando vemos o tamanho de um arquivo, sua extensão, a data de criação ou de modificação. São todos metadados que dão informação sobre um documento que em si já carrega uma série de dados [desestruturados nesse caso]. Esse post mesmo tem seus metadados: tags, categorias, data de publicação, autor etc.
Granularidade
Uma das questões que mais geram discussão no contexto de um trabalho que envolve dados é a granularidade com que eles serão coletados e armazenados. Uma mesma informação pode ser quebrada em diversas escalas, das maiores às menores. Por exemplo, a dimensão de tempo pode ser usada em anos, meses, semanas, dias, horas, minutos etc. Quanto menor a escala, maior a granularidade exigida.

E essa decisão tem um alto componente estratégico, porque quanto maior a granularidade, maior a capacidade de análise. Ao mesmo tempo, maior é o custo e a complexidade da operação. A decisão aqui gira em torno do quanto é necessário de granularidade para a natureza do negócio e das análises.
Dentro dessa discussão, é importante ter em mente dois conceitos importantes:
Dados desagregados
São dados estruturados, separados caso a caso. São conjuntos de dados totalmente crus, que não sofreram nenhum tipo de processamento e se mantém inalterados em relação ao processo de coleta. Por exemplo, os registros de cada aluno matriculado em uma turma de graduação e seus dados individuais de inscrição. São os dados mais granulares possíveis.
Dados agregados
São dados também estruturados, mas agrupados de alguma maneira, ou seja, que sofreram algum tipo de processamento analítico, buscando uma análise segmentada, perdendo granularidade. Continuando no exemplo da faculdade, seriam os alunos separados por sala, por trimestre ou por disciplinas. Esse tipo de dado costuma ser muito pior que o dado agregado para análises estatísticas e modelagens.
Variáveis
Finalmente, chegamos ao conceito de tipo de variável, algo muito importante para entender as possibilidades que o estatístico tem para trabalhar nos testes e técnicas que pretende utilizar. Nesse sentido, temos duas grandes classes:
Variáveis numéricas
São informações quantitativas, expressadas em um banco de dados na forma de números. Por exemplo: quantidade de filhos, de eletrodomésticos, o salário de uma pessoa, sua altura. São todas informações que remetem a quantidade, a valores numéricos. No caso de terem natureza sequencial, como salário ou altura, são chamadas de contínuas. E no caso de serem números específicos, fora de uma régua natural – como número de filhos ou eletrodomésticos – são chamadas de discretas.
Variáveis categóricas
São informações qualitativas, expressadas normalmente na forma de texto. Por exemplo: profissão, sexo, escolaridade, nível de proficiência em uma língua, etc. São categorias de resposta em que você pode se enquadrar, como masculino/feminino, básico/intermediário/avançado, fundamental/médio/superior e assim por diante. Às categorias que têm relação sequencial como escolaridade ou nível de proficiência em línguas, dá-se o nome de ordinais. Às que não tem relação nenhuma como profissão ou sexo, são chamadas de nominais.

Variáveis dummy
São variáveis categóricas binárias [0-1] que demonstram ausência ou presença de determinada condição. Por exemplo, se você quer ter em um banco de dados a informação da ocorrência ou não de chuvas. O cuidado aqui é para não confundir variáveis dummy com variáveis categóricas expressas em números, como forma de transposição para um banco de dados [Ex: básico = 1; intermediário = 2; avançado = 3].
Conclusão
Importante reforçar que aqui não estão todos os tipos de dados existentes, até porque muitos desses têm suas próprias subclassificações e o assunto é muito extenso. Mas conseguimos cobrir aqueles tipos de dados que são mais comuns no mercado e entre as pessoas técnicas da área de estatística e Data Science.
O mais importante de tudo é entender como navegar entre esses conceitos na hora de tomar decisões, sejam elas de formatação de banco de dados ou até mesmo nos modelos de coleta e armazenagem, não confundindo ou misturando tipos de dados distintos e correndo o risco de inviabilizar determinadas análises por conta disso.


