

Há muitas incertezas sobre o futuro do mundo, os rumos da economia e sobre a situação de saúde mundial por conta dos desdobramentos da pandemia do Coronavírus. Os números de mortes, contaminados e curados estão aí para quem se aventurar a analisar. O problema é que os dados estão espalhados por todo o lugar e as variáveis em cima deles tornam qualquer previsão um ponto de interrogação.
Cerca de 200 mil americanos vão morrer, segundo o Centro de Controle e Prevenção de Doenças, como mostra essa reportagem do The New York Times. Ou podem ser 2,2 milhões, segundo estimativa do Imperial College London divulgada no The Washington Post. Para o Brasil, a mesma instituição londrina estima que a taxa de contágio é a maior entre os 48 países analisados, conforme reportagem do Correio Braziliense. Já um estudo da Unicamp divulgada pela Revista Época projeta entre 18 mil e 120 mil óbitos.
Por que há tanta diferença nas previsões, com tantos números à disposição? Bem, a questão está em quais dados são coletados e como são coletados. No mundo da Data Science, chamamos isso da etapa de Preparation.
A matemática do Coronavírus
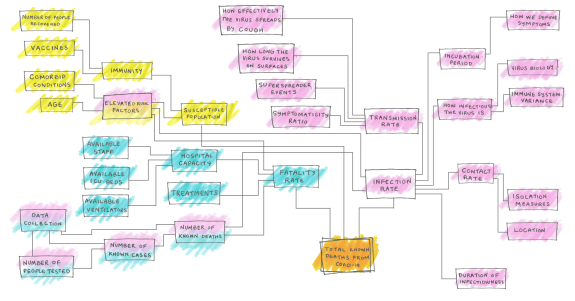
O modelo matemático para prever a quantidade de mortes é considerado simples: o número de pessoas que morrerão é uma função de quantas pessoas podem ser infectadas, como o vírus se espalha e quantas pessoas o vírus é capaz de matar.
Em outras palavras (mais matemáticas):
N (morto) = N (população suscetível) x taxa de infecção x taxa de mortalidade

O problema é que toda variável depende de várias opções e lacunas de conhecimento. E não há um único número absoluto para preencher os modelos. Eles divergem. E se cada parte individual do modelo matemático for instável, a variação de resultados vai ser, por exemplo, entre 200.000 e 2,2 milhões. Uma margem gigante de 2 milhões para mais ou para menos. E estamos falando de vidas aqui!
A entrada de dados
O que ocorre globalmente é que países, estados e cidades coletam dados de maneiras diferentes. Não há um padrão estabelecido, não há um sistema ou mesmo uma planilha compartilhada que centralize as informações.
As diferenças também se aplicam aos testes do Covid-19. Isso afeta o dado de quantas pessoas realmente contraíram o vírus e quantas testaram negativo.
O vírus em si também é imprevisível, afetando alguns grupos mais que outros. O local, a temperatura, o clima, o acesso a serviços de saúde, a densidade demográfica, as condições de vida da população, entre outros fatores, são determinantes para medir o impacto nas comunidades.
O cálculo da taxa de mortalidade também está confuso desde o início. Fatores como a incidência de diabetes entre a população do país, o número de idosos residentes ou uma população mais jovem influenciam diretamente. Saber a taxa de mortalidade até então na China, na Espanha e na Itália, por exemplo, ajuda na previsão, mas apenas reduz a incerteza, não serve de parâmetro exato para as medições no Brasil ou em todos os países.
A coleta de dados básicos
Não é possível saber a taxa real de mortalidade por várias razões, mas principalmente por conta da coleta de dados básicos sobre casos de Covid-19. Os números em si não traduzem os fatos. Eles são o resultado de registros que precisam ser documentados de forma transparente e detalhada antes de lançar um olhar completo e amparar tomadas de decisões.
Há de se considerar os dados não coletados e os imprecisos. Para determinar a taxa de mortalidade, deve-se dividir o número de pessoas que morreram da doença pelo número de pessoas infectadas com a doença. Nesse caso, não se tem realmente uma contagem confiável para o número de pessoas infectadas – portanto, para dizer matematicamente, não conhecemos o denominador.

Esse cenário também se aplica para a taxa de infecção: as estimativas são afetadas pela coleta de dados, amostragem e taxas de sintomatologia – pessoas que estão com a doença, mas não possuem sintomas. Mas, para conhecer a taxa de infecção, também é preciso descobrir com que frequência o vírus se move de uma pessoa para outra. A transmissão provavelmente será extremamente variável, dependente de todos os tipos de comportamentos sociais, detalhes ambientais locais e decisões políticas. Não será o mesmo de um país para outro. Provavelmente não será o mesmo de um estado para outro. Isso mudará com o tempo, dependendo das ações de combate ao vírus.
Por isso, modelar os possíveis resultados do Coronavírus significa experimentar vários cenários de transmissão diferentes, com uma variedade de estimativas, sendo que cada estimar é variável também.
A biologia de vírus também é importante quando você está tentando calcular transmissões por contato. Isso inclui o tempo de sobrevivência do vírus sobre superfícies e até que ponto ele pode estar presente no ar.
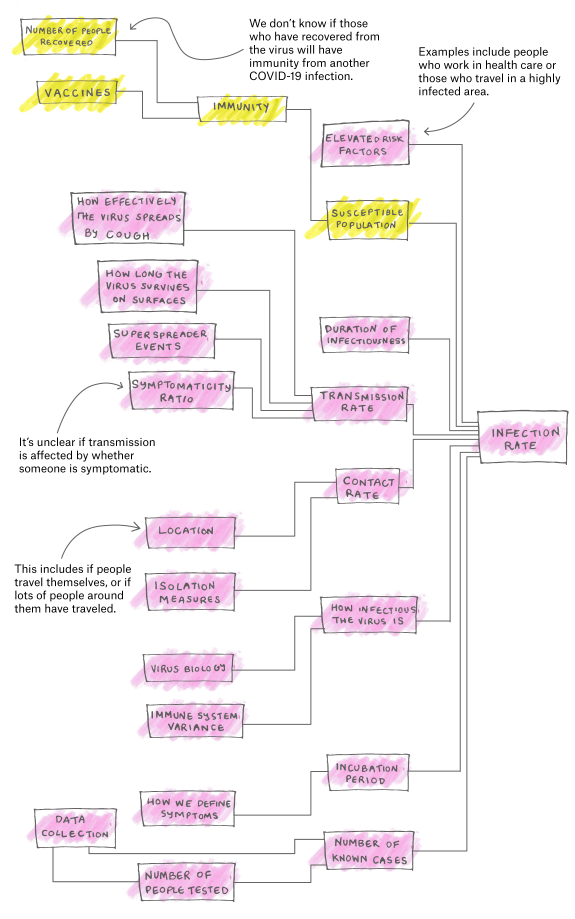
Finalmente, há a duração da infecciosidade – por quanto tempo uma pessoa pode espalhar o vírus para outras pessoas e quando, durante a progressão da doença, é infecciosa. Isso varia com a biologia do vírus e com o sistema imunológico individual. Todos esses parâmetros são usados para estimar a taxa de reprodução do vírus.
Foco em como os dados são coletados
A realidade é que os dados são uma expressão precisa de um processo subjetivo de como foi o processo de sua coleta. Ele ocorreu através de pessoas e pessoas não são exatas.
Não existe um conjunto de dados verdadeiramente “completo”, pois o processo de criação de dados envolve necessariamente decidir não coletar informações sobre determinadas entidades ou atributos dessas entidades. Sempre há mais coisas que se pode medir. Portanto, é crucial pensar no que não está sendo visto nos dados e no que está contemplado.
Neste contexto é essencial entender como e por que os dados são amostrados da maneira que são e considerar a consistência da abordagem. Frequentemente, os dados escolhidos para o uso A tornam-se inválido para os usos B, C e D, como para medir a mortalidade do Covid-19. Um conjunto de dados criado por alguém que está tentando vender algo deve ser pensado de maneira diferente daquele criado por uma parte mais neutra.
O site Our World in Data, por exemplo, possui gráficos que são obtidos diariamente no Centro Europeu de Prevenção e Controle de Doenças. Existem outros sites, mas com fontes semelhantes: uma coleção de casos relatados e mortes por país.
Nesse caso, os dados são coletados principalmente pelas autoridades de saúde de cada país para informar o governo nacional sobre como o vírus está se espalhando e sobre a pressão exercida sobre seus serviços de saúde.
Isso significa que os dados tendem a se concentrar nos casos que afetam o sistema de saúde e são mais adaptados às necessidades de cada governo nacional, com menos visão da consistência global, e sem levar em tão em conta as particularidades de cada parte isolada dentro do país.
O que tudo as empresas tem a aprender com isso?
Os esforços da Data Science para prever o comportamento do Coronavírus ensina muito para negócios, principalmente a importância de uma boa coleta e organização dos dados e informações antes de fazer quaisquer tipos de análises, previsões ou desenvolver modelos e algoritmos que embasem tomadas de decisões.
Por exemplo: se eu quero melhorar a atração de clientes em meu Funil de Vendas, preciso decidir quais dados serão utilizados para trabalhar este cenário. O que, em números, é considerado uma venda concretizada para minha empresa? O valor firmado em contrato, o valor final da Nota Fiscal já com a dedução dos impostos ou apenas o lucro já calculando os custos operacionais?
Definições iniciais como essa podem modificar toda a análise e, consequentemente, gerar insights e sugerir decisões distintas a serem tomadas posteriormente.
Conclusão: atenção aos ingredientes
O ponto principal é: tratar os dados não como uma verdade objetiva, mas como um reflexo do seu processo de coleta, com os objetivos e olhar de quem entendeu ser importante e viável de registrar.
Colocando em sentido figurado, a análise e a ciência de dados podem ser encaradas como fazer um bolo. Se a receita normal é seguida é possível esperar um resultado previsível que faça sentido. Mas se a receita tem instruções como “coloque entre 03 e 16 ovos, 02 xícaras de leite ou 08 colheres de manteiga, e cubra com 01 pacote de coco ralado ou 02 latas de brigadeiro, dependendo do que você possuir em casa”, isso afetará o sabor desse bolo, não é?

É permitido fazer suposições sobre os ingredientes corretos e sua quantidade. Mas essas são suposições – não fatos absolutos. E se muitas suposições ocorrerem no processo de misturar os ingredientes e assar o bolo é provável que o resultado seja totalmente diferente do que o desejado.
O mundo tem fome, então alguém precisa assar o bolo. Mas não sem antes perguntar quais ingredientes vão nesse bolo e quais as quantidades.
Antes de pensar em modelagem sofisticada, aprendizado de máquina de ponta e Inteligência Artificial, é preciso garantir que os dados estejam prontos para análise – esse é o domínio da preparação de dados.
* Conteúdo produzido com base no artigo do site Five Thirty Eight


